bead: Chaining your data and code together
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How do you ensure that your data products are reproducible?
Objectives
Use
bead, a command-line tool to create, update and share data products.
The problem
Researchers and analysts need to know the provenance of their data to trust its integrity and to quickly redo the analysis when requirements change. However, in a diverse and agile team, knowledge about data is often tacit, and is destroyed when a team member leaves. This leads to a duplication of effort. Additionally, the multitude of software tools and work methods create frictions in the analytics process. Existing solutions are either too rigid to be widely adopted or involve too much face-to-face communication, reducing researcher and analyst productivity.
bead is a lightweight software tool with which a researcher can explicitly declare dependency on other data products, referring to them with a universally unique identifier. She can see how her work fits in the bigger picture and who to work with when redoing the analysis. Bead encapsulates data, the software script that created it and references to its dependencies in a single package, making knowledge about the data explicit. Bead is platform independent and agnostic to the specific software tools and workflows used to create data. It can be adapted to any workflow that uses the file system for both scripts and data. Sample use cases include social and business datasets of a few GB each, processed and analyzed with perl, Python, R, Stata, Matlab, julia or other scripts.
Basic logic of bead
Given a discrete computation of the form
output = function(*inputs)
a BEAD captures all three named parts:
output- data files (results of the computation)function- source code files, that when run hopefully computeoutputfrominputsinputs- are other bead’outputand thus stored as references to those beads
As a special case pure data can be thought of as constant computation having only output but neither inputs nor source code.
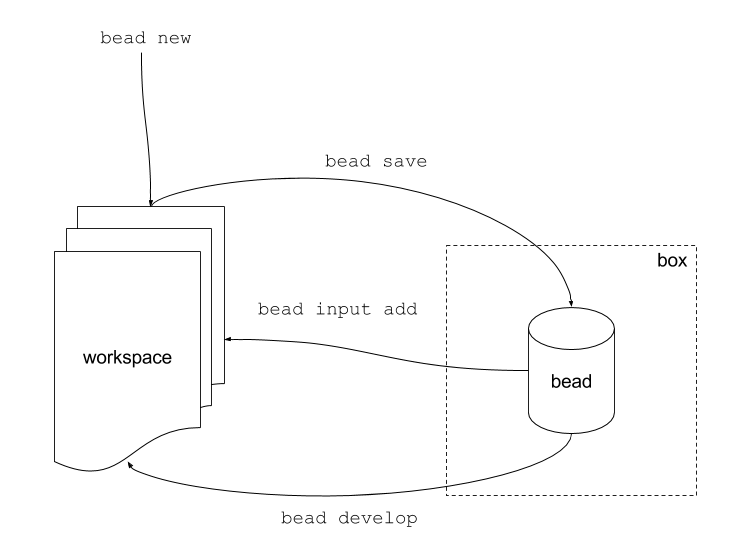
Bead concepts
Data packages can be in one of two states. Under active development in a workspace, or packaged and stored as a bead. Beads are stored in a box, which is just a collection of completed beads.
To see how workspaces are created from beads and vice versa, also see usecases
Workspace
A workspace is a directory, where the user works. It contains a prototype of a bead - it is a computation under active development. At some time however it is supposed to have all the inputs, code and output of a computation.
The directory has special structure and content, so it must be created via the bead tool:
- there are metadata in a hidden .bead-meta directory which .txt file enumerate all the inputs and the bead unique hash id.
- there are 3 standard directories with special meanings:
input: where input data is read from. It is read only, managed by thebeadtool.temp: temporary outputs, this is an area that is ignored when saving the bead.output: This is where results of the computation are stored.
Bead
A bead is a frozen, discrete computation, created from a workspace. It is currently a zip file.
A bead is intended to capture data with the code that produced it. The goal is transparency and semi-automatic reproducability through extra tooling. Full automatic reproducability is assumed to be inpractical/expensive, however it can be achieved by gradual process/quality improvements (learning through feedback).
The bead format is designed to be
- resilient to change
- decentralized
- keep enough information to be able to get both the details and the big picture (if all relevant beads are available)
The main technology involved is a combination of different probabilistic identifiers (UUID, secure hash, Merkle-tree).
Main properties of a bead:
kindthat is shared with other versions of a bead (book analogy: ISSN)- it is a technical name, whose existence allows the human name to change/evolve/diverge over time, while still referring to conceptually the same computation
content_id, that is unique for every bead (~version, book analogy: ISBN)- it is calculated, so changes in a bead makes it either invalid or a new version
- freeze time (for ordering versions, this is fragile in theory as depends on correctly set clocks, but in practice it is expected to cause few problems)
- freeze name
- references to its inputs (
kind,content_id)
The main changes from v. 0.0.2. to 0.8.1 that beads are referenced by names from here on.
It is important to mention that we should not create a new bead with a name already in use.
Box
A box is where beads are saved to and loaded from. It also gives names to beads and provide minimal search functionality. Currently, boxes are implemented a flat directories on the file system.
Installing bead
- install python if not already installed. Latest release depends on Python 3.8.5.
- download latest version from https://github.com/e3krisztian/bead/releases/tag/v0.8.1
you will need only the platform specific binary:
beadfor linux & macbead.cmdfor windows
- put the downloaded file in a location, that is on the PATH
for Linux known good locations are:
$HOME/bin(single-user, laptop, desktop, traditional location)$HOME/.local/bin(single-user, laptop, desktop, new XDG standard?)/usr/local/bin(system, servers, multi-user) for windows the python/scripts directory is a good candidate.
- (linux and mac only): make the file executable
For user install, the directories do not exist by default and they are only added to the PATH if exist.
E.g. the following commands would install version v0.8.1 (latest release at the time of writing) on linux:
# ensure user bin directory existst (for user specific scripts)
mkdir -p ~/.local/bin
# download bead
cd ~/.local/bin
wget https://github.com/e3krisztian/bead/releases/download/v0.8.1/bead
# make executable
chmod +x bead
# go back to work directory
cd -
(source: https://stackoverflow.com/c/ceu-microdata/questions/18)
Basic workflow
Bead help
The bead help guide you through the usage of the bead.
$ bead -h
usage: bead [-h] {new,develop,save,status,nuke,web,zap,xmeta,version,input,box}
positional arguments:
{new,develop,save,status,nuke,web,zap,xmeta,version,input,box}
new Create and initialize new workspace directory with a new bead.
develop Create workspace from specified bead.
save Save workspace in a box.
status Show workspace information.
nuke No operation, you probably want zap, to delete the workspace.
web Manage/visualize the big picture - connections between beads.
zap Delete workspace.
xmeta eXport eXtended meta attributes to a file next to zip archive.
version Show program version.
input Manage data loaded from other beads...
box Manage bead boxes...
optional arguments:
-h, --help show this help message and exit
All the positional arguments have own subcommands with complete help.
$ bead new -h
usage: bead new [-h] DIRECTORY
Create and initialize new workspace directory with a new bead.
positional arguments:
DIRECTORY bead and directory to create
optional arguments:
-h, --help show this help message and exit
Create a new bead
Initial setup.
The latest bead-box already made on the haflinger.
$ mkdir /somepath/bead-box/latest
$ bead box add latest /somepath/bead-box/latest
Will remember box latest
This is where completed beads will be stored. Create an empty bead with name name:
/somepath$ bead new name
Created name
Add some data to the output of this new bead which we can use later. This bead has no computation, only data.
/somepath$ cd name/
/somepath/name$ echo World > output/who-do-i-greet
/somepath/name$ bead save latest
Successfully stored bead.
cd ..
/somepath/$ bead zap name
Deleted workspace /somepath/name
Working with inputs in a new bead
Create a new data package:
/somepath$ bead new hello
Created hello
/somepath$ cd hello/
Add data from an existing bead at input/<input-name>/:
/somepath/hello$ bead input add name
Loading new data to name ... Done
Create a program greet that produces a greeting, using input/name as an input:
read name < input/name/who-do-i-greet
echo "Hello $name!" > output/greeting
Run the program:
/somepath/hello$ bash greet
This script has create a text file in output/greeting. Let us verify its content:
/somepath/hello$ cat output/greeting
Hello World!
Visually display the bead chain
Bead web is a new feature of version 0.8.1. You can check the details with bead web -h
$ bead web color auto-rewire heads / source-bead target-bead / png filename.png
Auto-rewire is required for the new bead.
Color is optional.
Heads are optional: if loaded they will only plot the latest version of each bead plus what is referenced by another bead.
If you change the source bead to .. it plots the entire bead structure leading to the target bead.
If you change the target bead to .. it plots the entire structure starting from the source bead.
It is very important that before and after / you need a space character.
Instead of png it can be svg filename.svg if you prefer that format.
Package the data and send it to an outside collaborator
Save our new bead:
/somepath/hello$ bead save latest
Successfully stored bead.
This stores output, computation and references to inputs. Now the content of /somepath/BeadBox is
/somepath$ ls -1 BeadBox/
hello_20160527T130218513418+0200.zip
name_20160527T113419427017+0200.zip
These are regular (and, in this case, small) zip files, which can be transferred by usual means (e.g. emailed) to collaborators. The recipient can process them via the bead tool, keep the integrity of provenance information, and adding further dependencies as needed. Even withouth the tool, she can access the data by directly unzipping the file and inspecting its content.
The output of the computation is stored under data/*. An outide collaborator without access to bead can just ignore the computation and all other metadata.
/somepath$ unzip -p BeadBox/hello_20160527T130218513418+0200.zip data/greeting
Hello World!
/somepath$ unzip -v BeadBox/hello_20160527T130218513418+0200.zip
Archive: BeadBox/hello_20160527T130218513418+0200.zip
This file is a BEAD zip archive.
It is a normal zip file that stores a discrete computation of the form
output = code(*inputs)
The archive contains
- inputs as part of metadata file: references (content_id) to other BEADs
- code as files
- output as files
- extra metadata to support
- linking different versions of the same computation
- determining the newest version
- reproducing multi-BEAD computation sequences built by a distributed team
There {is,will be,was} more info about BEADs at
- https://unknot.io
- https://github.com/ceumicrodata/bead
- https://github.com/e3krisztian/bead
----
Length Method Size Cmpr Date Time CRC-32 Name
-------- ------ ------- ---- ---------- ----- -------- ----
13 Defl:N 15 -15% 2016-05-27 13:01 7d14dddd data/greeting
66 Defl:N 58 12% 2016-05-27 13:01 753b9d15 code/greet
742 Defl:N 378 49% 2016-05-27 13:02 a4eb5de9 meta/bead
456 Defl:N 281 38% 2016-05-27 13:02 9a206f53 meta/manifest
-------- ------- --- -------
1277 732 43% 4 files
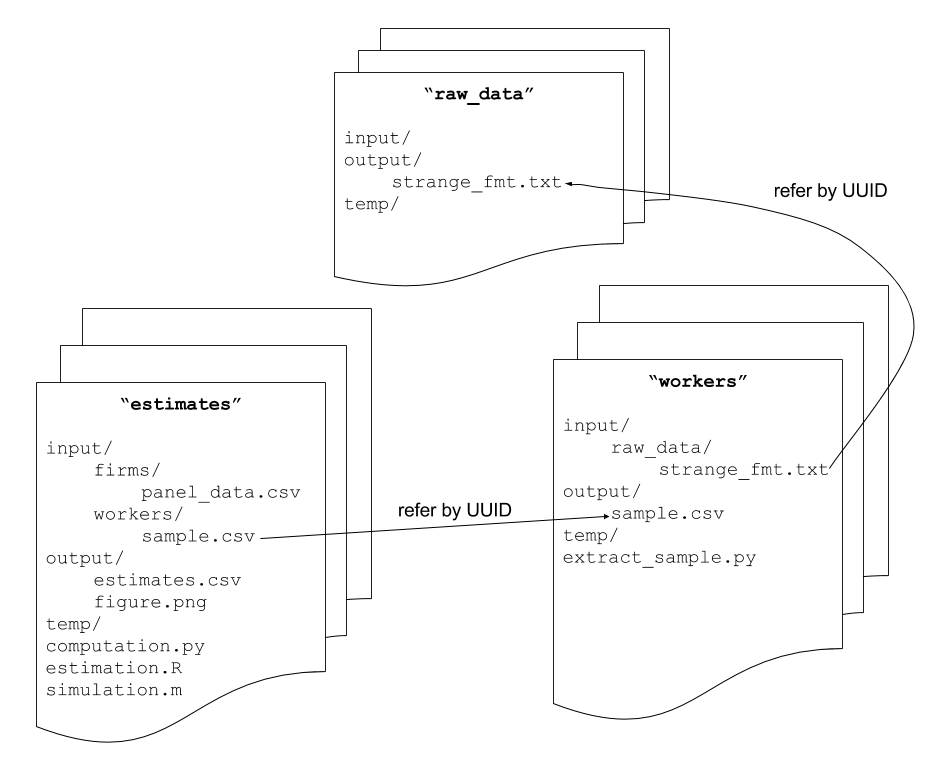
The following graph summarizes the internal structure of a workspace and the logical links to other beads.
Bead boxes
Key Points
Keep and share data together with the code that produced it.
When sharing your data, always do it in a bead.
Never refer to external data from a bead, use bead inputs.