Key datasets in MicroData
Overview
Teaching: 0 min
Exercises: 0 minQuestions
Which are the most important datasets and how to join them together?
What is an LTS dataset?
Where do I find the datasets on the server?
Objectives
Understand the difference between primary and foreign keys
Get to know major databases
Main datasets
The three main important datasets are the merleg-LTS-2019, the cegjegyzek-LTS-2019 and the procurement-LTS-2019.
The meaning of LTS is long-term support and 2019 is the input year when the data arrived.
The merleg data updates are arriving in December and contains information of the previous tax year. In the 2019 version the last tax year is 2018. The merleg database are processed version of the income statements, the balance sheet (assets and liabilities) and the additional annexes.
The cegjegyzek updates are arriving every year at May and contains information till that date.
LTS
The long-term support database idea comes from software development.
https://en.wikipedia.org/wiki/Long-term_support
Our LTS products will be upgrading every year at a given date. The users can count with the new versions and have enough time to prepare their scripts on them.
Every time when we make a new LTS there is a possibility to add new feature request. Before every version update the team talk trough which feature requests will be in each releases.
Primary keys
The Primary key constraint uniquely identifies each record in a table.
Primary keys must contain UNIQUE values, and cannot contain NULL values.
A table can have only ONE primary key; and in the table, this primary key can consist of single or multiple columns (fields).
https://www.w3schools.com/sql/sql_primarykey.asp
Frame_id
Frame_id is the primary key in most of our datasets represents a unique identifier for each corporation in our data. The unit of observation is an incorporated business entity. Frame_id connects companies transformed from one predecessor to one successor. It is based on registry court columns and announcement information about the transformation of companies. It aims to prolong the life of companies by not breaking the life cycle when a company changes tax number during transformation.
Frame IDs that start with “ft” are created from a tax identifier of the firm. Frame IDs that start with “fc” are created from a cégjegyzékszám. This means that the variable is composed of a notation “ft” and the first tax number in time. Any number could appear after “ft”, the use of the tax_id is left only to help with verification but it is better not to use it as a valid tax number.
Tax_id and originalid
Tax id could be primary or foreign key also.
From the full length 11 character long tax_id we use the prime number the first eight character of the id.
More information about the Hungarian tax ids:
https://hu.wikipedia.org/wiki/Ad%C3%B3sz%C3%A1m
The variable called originalid in merleg database is basically a tax id where we use a fictive negative number if we have a missing tax_id.
In the merleg database we drop the tax_ids starts with 15,16,19 or if they bigger than 3000001.
More about Hungarian tax_id character meanings:
https://drive.google.com/file/d/1mxWv2Pz2bES-5dDo-FUWj83wYJImvOCR/view?usp=sharing
Detailed meta information about the main datasets
merleg-LTS-2019
The detailed variable descriptions and development history are in the merleg-LTS-2019 bead output folder. The most important merleg related variables are the following:
variable name type format variable label
frame_id str15 %15s Frame_id identify one firm. Only_originalid if not valid
originalid long %10.0g Given year Taxid. Minus if taxid not valid
year int %9.0g Year 1980-2018
sales double %12.0g Sales 1000HUF
sales18 double %12.0f Sales in 2018 price 1000HUF
emp double %9.0f Employment clean v2
export double %12.0g Export sales 1000HUF
wbill double %12.0g Wage bill, Bérköltség 1000HUF
persexp double %12.0g Payments to personnel, Szemráf sum 1000HUF
pretax double %12.0g Net profit before taxation 1000HUF
teaor03_2d byte %9.0g 2 digit TEAOR03
teaor08_2d byte %9.0g 2 digit TEAOR08
gdp double %10.0g Gross Value Added: sales+aktivalt-ranyag 1000HUF
gdp2 double %10.0g Gross Value Added:(persexp+kecs+ereduzem+egyebbev)-egyebraf 1000HUF
ppi18 double %10.0g Producer price index 2018=1
so3_with_mo3 byte %9.0g State and local government owned dummy with ultimate owners from Complex
so3 byte %9.0g State government owned dummy with ultimate owners
fo3 byte %8.0g Foreign owned dummy with ultimate owners from Complex
do3 byte %9.0g Domestic owned dummy which is not so3 or fo3
mo3 byte %9.0g Local government owned dummy which is not so3
Cegjegyzek-LTS-2019
Organization of information in files
Entities
In the different relation files contain fields (owner_id, manager_id, frame_id, person_id_1, person_id_2) for entities designated with ids. In manage.csv and own.csv the type field (manager_type, owner_type) containing two-part strings separated with a hyphen, in the first part ‘HU’ stands for hungarian, domestic entity, while the second part designates whether it is a person (‘P’), a firm (‘F’), a municipality owned (‘MO’), a central government owned (‘SO’) or other unspecified (‘O’) type entity. The entity ids can take one of the following form:
Frame ID
See frame_id section.
Person ID
If an ID starts with ‘P’ it uniquely designates a person with hungarian name. If it starts with ‘PP’ the uniqueness is derived from knowing both the own and mother’s name of the person, if it starts with ‘PHM’ the uniqueness is based own husband’s and mother’s name, if it starts with ‘PR’ the uniqueness is based on rarity of the name.
Public owned entity ID
For hungarian public (i.e. state or municipality) owned entities we used the pir id, which is a 6-digit number. The ‘SO001’ stands for state ownership through non specified entity. ‘10011953’ designates the Hungarian National Bank, which has no pir id. The ‘entity/pir.csv’ contains the pir number and the corresponding entity.
Mock ID
If an ID starts with ‘FP’ it is a mock id, which means it is neither a uniquely resoluted person with hungarian name, or a hungarian corporation or a state owned entity. Entities with this ID are unique within but not across corporations.
Address ID
Address IDs are structured like this:
CC-SSSSS-DD-AA-WWWWW-TT-N(NNN)
Where:
- CC: Two-character country code, e.g.: HU
- SSSSS: Settlement code. For Hungarian addresses this is the KSH Code.
- DD: District. For Budapest the actual district, 00 if unknown. For cities with suburbs it should be 01 for the city itself, and 02, 03, 04 etc. for the different suburbs.
- AA: Larger administrative area (county, only for hungarian addresses)
- WWWWW: Public way name. The same name should have the same ID across settlements.
- TT: Public way type/Street suffix. The same type should have the same ID across settlements. The key for this is in entity/official_domain_names.csv
- N(NNN): The number of the building. If a building has a span of numbers, the lowest should be used. E.g. in case of Nador utca 9-15, number 9 is to be used.
For now, we don’t identify floors and door numbers.
Direct relations
Direct relations are relations explicitly available in Corporate Registry. In these files the ‘source’ field contains a 4 part string separated by underscores designating the reference to the original CR data point, the 4 parts are the following: CR number (cégjegyzékszám), CR rubric (rovat), row number within rubric (alrovat_id) and the group prefix (the prefix of variable group within rubric row: ‘’, ‘p’, ‘pc’, etc.)
ownership - relation/own.csv
The table contains the ownership relations as they are documented in Corporate Registry. The entity designated with ‘owner_id’ is an owner in a hungarian corporation designated with the frame_id. The ‘owner_id’ can take a form of a person_id, frame_id or a tax_id of a state or municipality owned entity. The ‘share’ field is a ratio which shows the realtive share of the owner entity in the corporation. The ‘share_flag’ tells us about the quality of the data (empty string - no share data was avaialble, 0.0 - could not be tested against share emission data, 1 - total share counts add up to share emission data, 2.1-2.2 the share was corrected using emission data, 3 - messy share data). The ‘share_source’ indicates from which original data field the share comes from.
signature rights and board members - relation/manage.csv
This table contains the significant employees and board members (‘manager_id’) for a specific corporation (‘frame_id’). The data comes from rubric 13 (signature rigths) and 15 (board members) of the Corporate Registry. The ‘position’, ‘board’, ‘liquidator’, ‘self-liquidator’ fields designate the role played by the entity within the corporation. The ‘position’ field can be one of the following values: ‘1’ - CEO, ‘2’ - significant manager, 3 - other employee, 0 - no specific information.
Indirect relations
Firm and person networks based on ownership and location
The outputs are temporal edge lists. Each record in the output csv files contains an edge. Each record contains the nodes connected by the edge along with the beginning date and end date of the connection and the shared characteristic between the two nodes. If the end date of the connection is empty it means that the connection is still in effect. A network file may contain flags describing the type of connection. These flags are described below at the corresponding network. The code currently generates the following three network types:
Firm network based on common owner or manager
Two firms (identified by frame id) are connected if they share an entity (manager or owner, identified by manager_id or owner_id) at a given time period. The output contains mixed connections (i.e. person X is a manager at firm A and an owner of firm B at a given time period). The role of the person (or entity, an owner may be a firm for example) in the two firms is conserved by corresponding position variables taking the values “o” for owner and “m” for manager. If you need a network based on only ownership connections you can easily filter this output to those edges where both position variables take the value “o”. The same way it works for a manager based network.
Person network based on common firm
Two people (identified by manager_id or owner_id, but ONLY IF it is a proper person id) are connected if they are present at the same firm (as a manager or owner) at a given time period. The output contains mixed connections (i.e. person A is a manager at firm X while person B is an owner of firm X at a given time period). The roles of the people in the firm are conserved by corresponding position variables taking the values “o” for owner and “m” for manager.
Firm network based on common address
Two firms (identified by frame id) are connected if they share an address (hq, site or branch, identified by address_id) at a given time period. The output contains mixed connections (i.e. Firm A has it’s HQ at address X and Firm B has a branch at the same location). The role of the address in the two firms is conserved by corresponding type variables taking the values “h” for HQ, “b” for branch, and “s” for site.
## Schema
####entity/county_settlement.csv
settlement
county_code
####entity/HU-TTT.csv
pw_type
index
timestamp
####entity/official_domain_names.csv
Names
####entity/HU-WWWWW.csv
pw_name
index
timestamp
####entity/settlement_codes.csv
settlement
suburb
SSSSS
DD
####entity/county_codes.csv
irsz
county_code
####entity/pir.csv
pir
tax_id
name
settlement
####entity/frame.csv
frame_id
tax_id
ceg_id
name
is_alive
birth_date
death_date
is_hq_change
is_site
is_transforming
is_in_complex
is_tax_id_corrected
####relation/manage.csv
frame_id
source
manager_id
manager_type
sex
birth_year
valid_from
valid_till
consistent
address_id
country_code
board
position
self_liquidator
liquidator
####relation/own.csv
frame_id
source
owner_id
owner_type
sex
birth_year
valid_from
valid_till
consistent
address_id
country
share
share_flag
share_source
####relation/hq.csv
frame_id
address_id
source
valid_from
valid_till
####relation/site.csv
frame_id
address_id
source
valid_from
valid_till
####relation/branch.csv
frame_id
address_id
source
valid_from
valid_till
####relation/firm_network_common_owner.csv
edge_id
frame_id_1
frame_id_2
pos_1
pos_2
valid_from
valid_till
####relation/owner_network_common_firm.csv
edge_id
person_id_1
person_id_2
pos_1
pos_2
valid_from
valid_till
####relation/firm_network_common_address.csv
edge_id
frame_id_1
frame_id_2
type_1
type_2
valid_from
valid_till
Procurement-LTS-2019
The bead chain
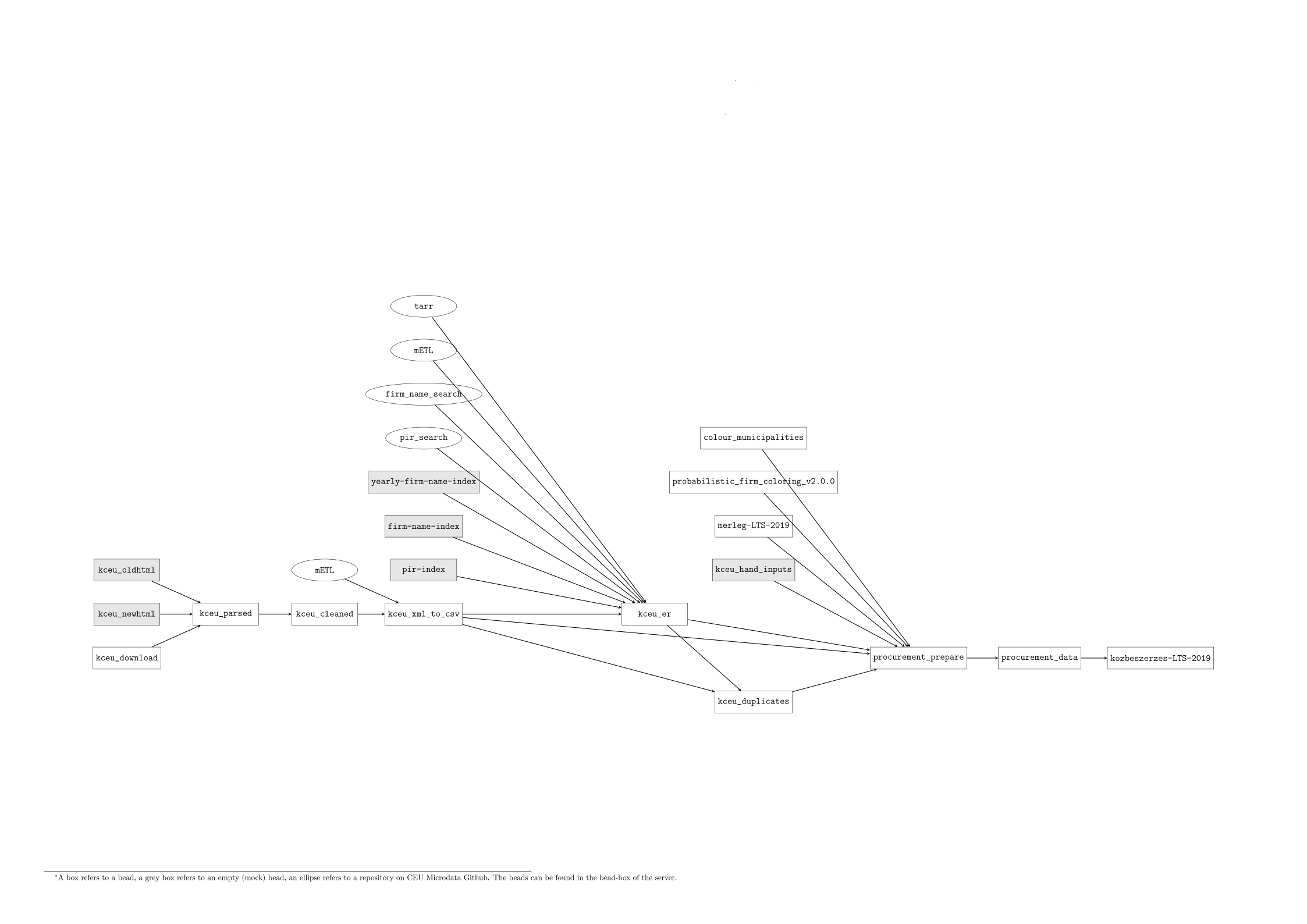
The input data is from the Procurement Authority website http://www.kozbeszerzes.hu. The final bead is the kozbeszerzes-LTS-2019.
The bead chain is made up of these elements:
-
kceu_oldhtml: Mock bead (output only). Contains tenders between 1997 and 2006. These files cannot be retrieved from the website anymore. The files are in html format in the output folder. -
kceu_newhtml: Mock bead (output only). Contains tenders between 2007 and 2017. These files have been downloaded by the scripts of thekceu_downloadbead (see below). The files are in html format in the output folder. -
kceu_download: Contains scripts for downloading tenders from the website for any arbitrary year. Currently it contains the 2018 tenders. The files are in html format in the output folder. -
kceu_parsed: Using the three above beads as input, it converts the tender html files to structured, hierarchical xml files by extracting the relevant pieces of information from the published notices. This bead mainly consists of an external parser and the modular parser. The external parser software works as a black box for us. The latter is an internal development which works for certain notice types, to improve the external parser performance. The output files are structured xml files for each tender. -
kceu_cleaned: Using thekceu_parsedbead as input, it removes empty tags from the xml files, and converts foreign currencies to HUF. -
kceu_xml_to_csv: Using thekceu_cleanedbead as input, it converts the xml (separate files for each tender) to different csv files. These arepart.csvwhich contains the basic information of the tenders (subject, cpv, value, etc.),requestor.csv,bidder.csv, and thewinner.csv, which list the relevant entities for each tender part. Note that the latter are intermediary products in the sense that entity resolution and deduplication is still to be carried out on these files (see below). -
kceu_er: Using the csv files of thekceu_xml_to_csvbead (and additional beads of firm and pir name indexes) as input, it applies entity resolution on the tenders (usingpir search toolandfirm name search tooldeveloped within Microdata): that is, it tries to identify the bidder, winner, and requestor firms and institutions using our databases at Microdata. The outputs are the resolved winner, bidder, and requestor csv files which will contain unique identifier (tax id or pir id) for entities so that it can be merged with another Microdata products. -
kceu_duplicates: Using thepart.csvfrom thekceu_xml_to_csvbead, and the resolved csv files of thekceu_erbeads, it identifies duplicate tenders. It is necessary because some tender result are announced multiple times at the official website for some reason (this is more frequent for older tenders). The identification is based on similarity of requestors and bidders, subject, value, and decision date. The output is aduplicates.csvfile which list the duplicate tender ids and indicates which lines to drop and which to keep. -
kceu_hand_inputs: Despite all our effort to convert every existing procurement data creation process into beads to guarantee reproducibility, there are some remaining files for which we could not identify the source code and/or are unique hand collected inputs that do not fit into standard bead structure. The output files of this empty bead serve as inputs for theprocurement_preparebead. -
procurement_prepare: This bead combines the output files ofkceu_xml_to_csv,kceu_er,kceu_duplicates, and generates a tender part – bidder level datafile (all_bids.dta). Moreover, using mostlymerleg-LTS-2019and some other inputs such as probabilistic firm coloring, it prepares some auxiliary files which contain information on firms, pir entities, firms political connections, and election results. -
procurement_data: This bead builds solely upon the input files prepared in theprocurement_preparebead. Combining these files, it produces two types of output data ready for analysis: a tender – bidder level dataset calledprocurement_bids_data, which contains all the necessary information from the tender (subject, cpv, estimated value, final value, etc.), the requestor and bidder entities (location, NACE code, balance information, etc.), as well as the outcome of the tender.procurement_wins_datais essentially the same file, but for each tender only the winning bidders are included. The other type of output data calledgovernment_private_sales_datais a yearly panel of firms. Besides the most important balance information, it is a yearly aggregate of each firm’s procurement revenues, and based this the private revenues are also derived.
Media and scraped datasets
We have scraped, parsed and cleaned version of the biggest online media providers in the media-bead-box
We have firm year month unique information about advertisement data from 1991-2016.
Key Points
LTS dataset is supported in the same format at every update
LTS beads are more than just a bunch of beads: one LTS package is suitable for use in a large variety of research trends