Introduction
Overview
Teaching: 0 min
Exercises: 0 minQuestions
Key question (FIXME)
Objectives
First learning objective. (FIXME)
FIXME
Key Points
First key point. Brief Answer to questions. (FIXME)
Using the terminal
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How to navigate in the terminal?
How to execute commands and start applications?
What are some of the most important command line tools?
Objectives
Understanding how the command line interface works.
Learn the most important command line operations.
The Command Line Interface
You probably mostly use your computer via something called a GUI, or Graphical User Interface. Practically any modern operating system comes with a GUI. It is the GUI that, for example, allows you to instruct your computer to run applications by double clicking on an application’s icon instead of issuing your commands in writing.
However, it is not the only way to use your computer. Before the quick rise in computing capacity and memory, graphical interfaces were impossible to develop. Originally computers are instructed via written commands in something called a CLI, or Command Line Interface. Practically anything that is feasible using a GUI can be done using the CLI, even though it might be much more difficult. Then why bother with using the CLI at all? - you might ask. There are two main reasons for familiarizing yourself with the CLI at MicroData:
- The servers that we use have very limited graphical support, and you will mostly use an Ubuntu terminal when you work on the servers.
- Most freshly developed tools for data analysis simply do not have a GUI. It takes a lot of resources to develop GUIs, and most open source developers focus their attention to the core performance of the tools instead of a GUI. If you want to use these, you have to familiarize yourself with the CLI of your computer.
How are commands interpreted?
Every operating system comes with a command line interface. The CLI, just like the GUI is, however, different on each operating system. Most modern Windows operating systems use a CLI called Windows PowerShell, while Unix-like systems like MacOS, Ubuntu and other Linux distributions usually use a CLI called Terminal.
It is not only the name of the CLI that differs. The commands that you issue in the CLI have to be interpreted by the computer (translated to a long list of ones and zeros) in order to execute your commands. The way that commands are translated also differs across operating systems. Without going into too much details, it practically depends on something called the command line interpreter, which is a software that does this translation for you. On Windows, this is called cmd.exe, while on most Unix-like systems it’s called Bash. The main problem with having mulitple CLIs and command line interpreters is that they understand different commands and translate these commands differently. Something that works on Ubuntu will very likely not work on Windows and vice-versa.
However, as mentioned before, the command line interpreter is just a software. Some of these interpreters have versions available for many different operating systems. The most widely used interpreter is probably Bash. If you are using MacOS or Ubuntu, you are good to go, you already have Bash installed on your computer. If you work with Windows, then you have already installed Git-bash, which, as it’s name suggests, is a Bash interpreter. You will have to use this instead of the default Windows CLI throughout this episode.
The Terminal
The CLI that we are going to use is called the Terminal (on Unix-like systems) or Git-bash (on Windows). From here on, they both will be referenced as the Terminal. If you open a Terminal window, you are supposed to see an almost-blank window with something like this written on it:
johndoe@haflinger:~$
It should be followed by a blinking cursor. This is called the command prompt. It tells you some important information about where you are currently working. It is structured the following way:
username@machine:current_directory$
These are possibly the most important pieces of information that you need to be aware of when using the CLI. What do they tell you?
- username: This is your username on your computer. In most cases it will not change. In many systems you can switch to a user called root, that can do anything on the computer that a standard user cannot. You should only see your username there, if it changes you should close the Terminal and start a new session unless you are really sure about what you are doing.
- machine: This is separated from the username by an
@sign in most cases. It will change for example if you log in to the server. You will be able to control the MicroData servers using the Terminal as well. It is important to know whether you are controlling your own computer or the server in the Terminal window, always make sure that you are working on the proper machine. - current_directory: This is usually separated from the name of the machine by a colon. In many operating systems you have something called your home folder or user folder. It is usually referenced in the Terminal by the
~sign. If you change the working directory (which will be discussed in a second), it will change accordingly. For example on an other machine and in a different folder it might be something like this:johndoe@johndoe-DELL:~/Documents/onboarding/_episodes
In order to use your computer via the Terminal, you will have to type commands and press enter. They will be executed one-by-one. The rest of this episode will be about the most important commands in the Terminal.
The most important Terminal commands
Terminal commands can be executed by pressing enter after typing them. The general structure of a command is the following:
command <positional arguments> <optional arguments>. Some commands work by themselves, while others require arguments (for example if you want to change the working directory, you have to specify the new working directory). Positional arguments always have to be specified, while optional arguments are, as their name suggests, optional. You can almost always get a detailed explanation on the positional and optional arguments by opening up the manual of the command by executing man <command> or by calling the command with its help optional argument by <command> --help or help <command>
You can find the most commonly used commands with a short description below by categories. If you prefer, you can check out this Carpentries page, which contains a more detailed walkthrough for each command.
Navigation
-
pwdreturns the path to the current working directory. In most cases this is part of the command prompt, however, if you are deep down in the folder structure, the command prompt will only display a few parent directories.$ pwd~/Documents/GitRepos/CEU_MD_Onboard/onboarding/Now, we are at the ~/Documents/GitRepos/CEU_MD_Onboard/onboarding/ after typing the
pwd. (Don’t worry about the tilde (“~”) sign. You are going to learn about it in a minute. cdchanges the working directory. It has a positional argument, which is the target directory. The target directory can be either given as an absolute path or a relative path.#absolute path $ cd /srv/sandbox/ #relative path $ cd ../../srv/sandbox/In relative paths you can reference the parent directory by two dots
.., thus if you want to go to the parent directory, you should issuecd ... Some more commonly usedcdcommands:#Going to your home directory $ cd #going to the root folder $ cd / #going up to the parent directory $ cd .. #going to the Desktop directory in the home directory $ cd ~/DesktopThe tilde (“~”) character in the last command is a shortcut for indicating the home directory.
-
startwill open a file in the default application associated with it on Windows (aka your default application on Windows). -
openwill open a file in the default application associated with it on MacOS (aka your default application on MacOS). -
xdg-openwill open a file in the default application associated with it on Ubuntu and many other Linux distributions (aka your default application on any Linux distros).The example is opening a picture in the default picture viewer.
#On Windows $ start my-picture.png #On MacOS $ open my-picture.png #On (most) Linux distros $ xdg-open my-picture.png
File System Exploration
lslists the content of the current working directory. It has a wide set of optional arguments that you can combine to get a listing you prefer. A few of these are:-lwill give you the list of files with one file in one line, and it will include additional information on file permissions, file owners, file size and modification date.-awill list all files and folders including hidden ones.-Swill sort the files by size in descending order before listing them.-twill sort the files by modification time (newest first) before listing them.-rwill revert the order of files before listing them.-hwill display the file sizes in a human-readable format.- You can combine these options, so for example
ls -ltrhawill list all files, including hidden ones, in a list where one file will be one line, and the oldest file will be the first (notice the revert option, that is why it’s not the newest) and file sizes will be human-readable.
$ ls -ltrhalesswill show you the content of a text file. It has one positional argument, the text file. It’s worth noting that it can be any text file, for example.pypython codes can be viewed as well as.csvdata files.$ less trial.pyYou can scroll up and down using the arrows on your keyboard and exit by pressing
q.FIXME: Adding a table of useful
lessassociated keyboard combos-
filewill determine file type. In fact, one of the common ideas in Unix-like operating systems such as Linux is that “everything is a file.”$ file picture.jpgpicture.jpg: JPEG image data, JFIF standard 1.01
Files and Directories Manipulation
cpcopies a file. It has two positional arguments, the source file and the target file.#Copy a file to the parent folder $ cp my-file.txt ../my-file.txt #Copy a folder to the parent folder by using -R recursive option $ cp -R my-folder/ ../mvmoves a file or folder. It has two positional arguments, the source and the target path.#Move a file to the parent directory $ mv my-file.txt ../ #Move the directory "my-folder" and its content to the parent directory $ mv my-folder ../It is also the way to rename files.
#"old-filename.txt" will be renamed to "new-filename.txt" $ mv old-filename.txt new-filename.txtmkdircreates a new folder in the current working directory. It has a single positional argument, which is the name of the new folder.$ mkdir my-new-folderIt can also have multiple optional arguments if you wish to create multiple folders.
$ mkdir dir1 dir2 dir3It is even possible to create nested folder structures by providing the
-pargument.$ mkdir -p dir4/dir5/dir6-
rmdirremoves an empty directory. It’s only positional argument is the folder to be removed. It only removes empty folders, you need to delete it’s content first. rmremoves a file. It has a positional argument, which is a list of files to be removed. You can give multiple files separated by spaces to remove.#Remove a single file $ rm my-text.txt #Remove multiple files $ rm my-text.txt my-data.dtaIMPORTANT: If you remove a file by
rmit will be permanently deleted, be careful with it!- Recursive
rmremoves a directory with all of its subdirectories and files. It can be accessed with the-roptional argument.$ rm my_folder/ -rIMPORTANT: Recursive
rmwill remove the directory with all of it’s content permanently. - Recursive forced
rmremoves a directory with all of its subfolders and files even if the files are read-only. It can be executed using therfoptional argument.$ rm my_folder/ -rfIMPORTANT: deletion is permanent. You should not use it in general, it is only a last resort. The presence of read-only files strongly suggests that they should not be deleted using
rm, but in some other ways (e.g.bead nukein case of beads). There are some cases when this is useful, but use it with care and only if it is unavoidable. - Some useful shortcuts which could be used with the some of the above-mentioned commands:
?, a question mark can be used to indicate “any single character”.*, an asterisk can be used to indicate “zero or more characters”.
#Instead of using $ cat test_1.txt test_2.txt test_3.txt #Better usage is $ cat test_?.txt #An even shorter solution is $ cat test_*You are going to learn about
catcommand in the next section.
Redirection and some other useful commands
catwill print the content of files on your terminal screen. It’s positional argument is a file list separated by spaces.$ cat my-code.py
If you specify multiple files, it will concatenate (its name comes from here), meaning that linking together and output each of them, one after the other, as a single block of text as it could be seen at the end of the Files and Directories Manipulation section.
headandtailshows you the first and last few lines of a text file, respectively. It has one positional argument, the text file.$ head my-data.csv $ tail my-data.csvechowill print the value of its argument on your terminal screen.$ echo hello world!hello world!- Some, other useful commands and shortcuts:
-
>redirection operator will redirect standard output to another file instead of the screen. However, using this will ALWAYS overwrite the content of that file -
>>redirection operator will do the same as>does, BUT it will not overwrite the output file. Instead, it will append the content of that file. -
|pipeline operator connects the ouput of one command with the input of a second command. -
sortwill sort lines of text. -
uniqwill report or omit repeated lines. -
wcwill print newline, word, and byte counts for each file.wc -lonly counts the number of the lines. -
cutwill print selected parts of lines from each file to standard output. -
historywill display previous commands typed in the command line. -
nanowill open the Nano text editor. -
grepwill print lines matching a pattern.
For more information, please consult the Chapter 6 - Redirection in “The Linux Command Line” book.
-
File Permissions
For concise description, please visit the File Permissions section of the following link: https://datacarpentry.org/shell-economics/03-working-with-files/index.html /
Useful resources for learning Terminal:
- Introdutction to the Command Line for Economics: https://datacarpentry.org/shell-economics /
- Official Ubuntu tutorial: https://ubuntu.com/tutorials/command-line-for-beginners#1-overview /
- The Linux Command Line by William Shotts: http://linuxcommand.org/tlcl.php / (freely available)
Key Points
The computer can be controlled using a GUI or a CLI.
Anything that you can do using the GUI can be done using a CLI.
In the CLI, you have to issue commands with possibly some positional and optional arguments.
A quick introduction to Git and Github
Overview
Teaching: 0 min
Exercises: 0 minQuestions
What are the basic terms used by version control systems?
Which files are contained within the .git directory?
How to install git?
How does the basic collaborative workflow look like?
What are some of the most important git commands?
Objectives
Understand the basic terminology of Git and Github
Install and setup git
Understand the collaborative workflow and commit message etiquette
List some of the most useful commands that can be easily accessed in your everyday work
Version Control Basics
There are various Version Control Systems such as:
A version control system can be either:
- centralized - all users connect to a central, master repository
- distributed - each user has the entire repository on their computer
Terminology
Version Control System / Source Code Manager
A version control system (or source code manager) is a tool that manages different versions of source code. It helps to create snapshots (“commits”) of project files, thereby, supporting the tractability of a project.
Repository / repo
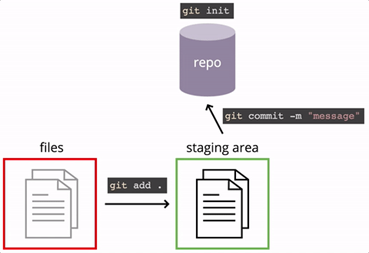
A repository is a directory which the version control system tracks and should contain all the files of your project. Besides your project files, a repository contains (hidden) files that git uses for configuration purposes. Git, by default, tracks all your files in a repository. If there are files you do not wish to track, you can include them in the manually created .gitignore file.
Repositories can be located either on a local computer or on the servers of an online version control platform (such as Github).
Staging Area / Staging Index / Index
Before committing changes to your project code, the files you want to snapshot need to be added to the Staging Index. Changes to these files can be captured in a commit.
Commit
A commit is a snapshot of the files that are added to the Staging Index. Creating a commit can help you to save a particular version of your project. When committing changes, you should also include a commit message that explains the changes of the project files since the previous commit. Therefore, commits track the evolution of your project and allows you to see the changes from one commit to another. It is also useful when experimenting with new code, as git makes it possible to jump back to a previous commit in case your code changes do not work out as planned.
SHA
A SHA(“Secure Hash Algorithm”) is an identification number for each commit.
It is a 40-character string composed of characters (0–9 and a–f) such as e2adf8ae3e2e4ed40add75cc44cf9d0a869afeb6.
Branch
A branch is a line of development that diverges from the main line of development. It further allows you to experiment with the code without modifying the line of development in the master branch. When the project development in a branch turns out successful, it can be merged back to the master branch.
Checkout
Checkout allows you to point your working directory to a different commit. Therefore, you can jump to a particular SHA or to a different branch.
.Git Directory Contents
The .git directory contains:
- config file - it stores the configuration settings
- description file - file used by the GitWeb program
- hooks directory - client-side or server-side scripts can be placed here to hook into Git’s lifecycle events
- info directory - contains the global excludes file
- objects directory - stores all the commits
- refs directory - holds pointers to commits (e.g “branch” and “tag”)
Install, setup git
- Supported browsers: current versions of Chrome, Firefox, Safari, Microsoft Edge
- Create a GitHub account
- Install git
- If you are on a Mac, git should already be installed.
- If you are using a Windows machine, this will also install a program called Git Bash, which provides a text-based interface for executing commands on your computer.
- Configure installation
git config --global user.name "your-full-name"git config --global user.email "your-email-address"
- SSH key: for faster usage (no password will be needed afterwards)
- Check if you already have: Is it anything in .ssh?
ls .ssh- if no, create a new one and add to ssh agent
- if yes, go to next step
- Add new SSH key to your github account
- Check if you already have: Is it anything in .ssh?
- Download Sublime Merge (recommended git client)
Git workflow
Making changes
git status,git init(store all changes you commit in this folder),git add(except.gitignore)git commitoften, to avoid conflict- commit message should be: If applied, this commit will “your message” (eg.
git commit -m "change label names"or “update README”). - commit message could also refer to Issues (eg. “close #3”) (issues are like to-do-s)
- commit message should be: If applied, this commit will “your message” (eg.
git log: view the history of commits you’ve made
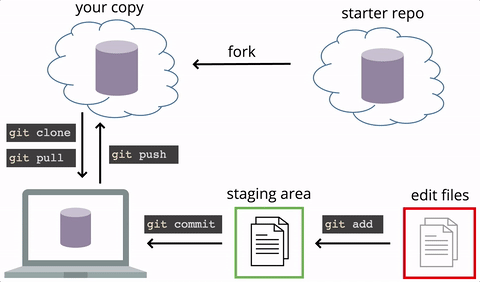
Collaborate with others
In practice, it is good to be sure that you have an updated version of the repository you are collaborating on, so you should git pull before making your changes. The basic collaborative workflow would be:
- update your local repo with
git pull origin master, - make your changes and stage them with
git add, - commit your changes with
git commit -m, and - upload the changes to GitHub with
git push origin master
It is better to make many commits with smaller changes rather than of one commit with massive changes: small commits are easier to read and review.
- fork: copy to origin / clone: copy remote repo to create local repo / pull: copies changes from a remote repository to a local repository.
- .gitignore (eg. large files OR on Mac hidden .DS_Store files OR data in ss-descriptives)
Branching, conflicts
Note, if someone pushes a commit to GitHub before you push your changes, you’ll need to integrate those into your code (and test them!) before pushing up to GitHub.
git diffdisplays differences between commits.git checkoutrecovers old versions of files /git revertbacks out commit Branchinggit branchcreates a new branchgit checkoutswitches to a different branch Merginggit mergemerges other_branch into the current branch
Conflicts occur when two or more people change the same file(s) at the same time. The version control system does not allow people to overwrite each other’s changes blindly, but highlights conflicts so that they can be resolved.
- Push: You will not be able to push to GitHub if merging your commits into GitHub’s repo would cause a merge conflict. Git will instead report an error, telling you that you need to pull changes first and make sure that your version is “up to date”. Up to date in this case means that you have downloaded and merged all the commits on your local machine, so there is no chance of divergent changes causing a merge conflict when you merge by pushing.
- Pull: Whenever you pull changes from GitHub, there may be a merge conflict! These are resolved in the exact same way as when merging local branches: that is, you need to edit the files to resolve the conflict, then add and commit the updated versions.

Useful commands
| Code | Short description |
|---|---|
git init |
Initialize local git repository |
git status |
Check the status of git repository (e.g. the branch, files to commit) |
git add |
Add files to staging index |
git add . |
Add all modified files to staging index |
git commit -m"Text" |
Commit changes with commit message |
git log |
Check git commits specifying SHA, author, date and commit message |
git log --oneline |
Check git commits specifying short SHA and commit message |
git log --stat |
Check git commits with additional information on the files changed and insertions/deletions |
git log -p |
Shows detailed information on lines inserted/ deleted in commits |
git log -p --stat |
Combines information from previous two commands |
git log -p -w |
Shows detailed information on commits ignoring whitespace changes |
git show |
Show only last commit |
git show <options> <object> |
View expanded details on git objects |
git diff |
See the changes that haven’t been committed yet |
git diff <SHA> <SHA> |
Shows changes between commits |
git tag |
Show existing tags |
git tag -a "tagname" |
Tag current commit |
git tag -d "tagname |
Delete tag |
git tag -a "tagname" "SHA pattern" |
Tag commit with given SHA pattern |
git branch "name_of_branch" "SHA pattern(optional)" |
Create new branch – at SHA pattern |
git branch “name_of_branch” master |
Start new branch at the latest commit of master branch |
git checkout “name_of_branch” |
Move pointer to the latest commit of the specified branch |
git branch -d “name_of_branch |
Delete branch, use -D to force deletion |
git checkout -b “name_of_branch” |
Create branch and checkout in one command |
git log --oneline --graph --all |
Show branches in a tree |
git merge “name_of_branch_to_merge_in” |
Merge in current branch to another |
Useful resources for mastering git and github:
- Technical foundations of informatics book: https://info201.github.io/git-basics.html
- Software carpentry course (Strongly recommended): https://swcarpentry.github.io/git-novice/
- Github Learning Lab: https://lab.github.com/
- If you are really committed (pun intended): https://git-scm.com/book/en/v2
- Getting started with Github: https://help.github.com/en/github/getting-started-with-github
- Git cheatsheet: https://education.github.com/git-cheat-sheet-education.pdf
- Learn git with bicbucket cloud: https://www.atlassian.com/git/tutorials/learn-git-with-bitbucket-cloud
Useful GUI tools for version control:
- Sublime Merge: https://www.sublimemerge.com
- Version Control in VS Code: https://code.visualstudio.com/docs/editor/versioncontrol
Key Points
How to use the haflinger server
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How to connect to haflinger server?
What is the structure of the server?
What is the general workflow on the server?
Objectives
Learn how to set up connection with the server
Understand the basic specifications of our server
Study commands that are useful when working on the server
The server and some basic information
Microdata currently uses one server.
- haflinger: haflinger.ceu.hu - function: STATA/Matlab/Python with graphical interface
The haflinger server has 504GB memory and 112 cores.
Connecting to the server from different local operating systems
First, you have to be connected to the CEU network through VPN. You can use the AnyConnect client or the openconnect package depending on your OS. For more information on VPN usage please visit http://www.it.ceu.edu/vpn and http://docs.microdata.io/vpn.
You can access the shell (command line) on haflinger.ceu.hu by using a Secure Shell (ssh) client, such as Putty (http://docs.microdata.io/putty). On UNIX-like systems the built-in ssh package allows you to connect without any additional software. This is where you can change your password, or where you can start batch jobs from the shell.
You can connect to the graphical interface (windows-like) on haflinger.ceu.hu via a VNC client. On UNIX-like systems using X-server (e.g. Ubuntu) you can simply allow X11 forwarding in an ssh connection by using the -X optional argument and don’t need a VNC client.
Linux
You can connect to the servers from a Terminal window using either of the following commands (substitute your username and port number appropriately):
$ ssh USER@haflinger.ceu.hu -p PORT -X
MacOS
You can connect to the servers from a Terminal window using either of the following commands (substitute your username and port number appropriately)
$ ssh USER@haflinger.ceu.hu -p PORT
For a graphical server connection a useful tool is XQuartz. Using XQuartz you can enable X11 forwarding. In an XQuartz terminal you can connect to the graphical server by issuing the following command: (substitute your username and port number appropriately)
$ ssh USER@haflinger.ceu.hu -p PORT -y
Windows
PuTTy provides a CLI for the server.
On Windows you can download a simple REAL VNC viewer from: vncviewer
After installation you have to use the following server address along with your server password:
haflinger.ceu.hu:VNCPORT
A good example how you can start the viewer from the cmd. You have to change the “%vnc_port%” part to your own port number.
$ vncviewer.exe -SecurityNotificationTimeout=0 -WarnUnencrypted=0 -Quality=High -Scaling=100%x100% haflinger.ceu.hu:%vnc_port%
Private and public keys for easier connection
For easier server access you can create private/public key pairs as follows:
-
Start the key generation program by typing
ssh-keygenon your local computer -
Enter the path to the file where it is going to be located. Make sure you locate it in your
.sshfolder and name it asmicrodata_kulcs(or any alternative filename). -
Enter a Passphrase or just simply press Enter. The public and private keys are created automatically. The public key ends with the string
.pub. -
Copy the public key to the
$HOME/USER/.sshfolder on the server. (substitute your username appropriately) -
An alternative solution for point 4 is using the following code:
ssh-copy-id -i ~/.ssh/id_rsa USER@haflinger.ceu.hu -p PORT. (a useful source for the whole process)
Finally, you can alias the command that connects you to server:
MacOS
Copy the following text into the config file which is located in your .ssh folder:
(substitute your usernames and port number appropriately)
Host haflinger
HostName haflinger.ceu.hu
User USER
Port PORT
IdentityFile /Users/LOCAL_USER/.ssh/microdata_kulcs
This allows you to connect to the haflinger server by typing the ssh haflinger command.
Linux
Add the following lines to your .bashrc file located in your home folder (by typing nano .bashrc):
alias haflinger='ssh USER@haflinger.ceu.hu -p PORT'
This allows you to connect to the haflinger server by typing the ssh haflinger command.
Windows
Structure of the server and general workflow
When connecting to the server, you are directed to your home folder `/home/USER_NAME’. Only you have access to your home folder and you can use it for developing your own projects.
For Microdata project work, however, you should be working in your sandbox located at /srv/sandbox/USER_NAME.
Working in your sandbox allows others to check your work and develop projects collaboratively.
When saving your bead, a copy of your work is created in .zip format in one of the beadboxes.
The beadboxes are located at /srv/bead-box/.
For more information on the use of bead, please visit the corresponding episode on this website.
Creating alias to your sandbox
You can create aliases that simplifies your access to you sandbox.
For that, you need to add the following commands to your .bashrc file: (substitute your username appropriately)
alias sandbox='cd /srv/sandbox/USER_NAME'
The .bashrc is located in your home folder (home/USER).
Then, you can access your sandbox by typing sandbox to the command line.
Useful server tools
File transfer to the server
To move data between your computer and the server, you need an SFTP or SCP client. You have access to your home folder, and you may access shared data and project folders. You can choose from a wide variety of SFTP clients. A few of these are the following:
- Filezilla - https://filezilla-project.org/
- On Windows you can use WinScp - https://winscp.net/eng/index.php
To access the files on the server, provide the following sftp address to your client along with your username, password, and appropriate port number:
sftp://haflinger.ceu.hu
It is worth noting that on Ubuntu systems you don’t need any additional client for file transfer. Just open a file navigator, go to Other locations, and connect to the server by issuing it’s sftp address - e.g. sftp://USER@haflinger.ceu.hu:PORT. You will automatically be prompted for your username and password, and you can navigate on the server just like on your own computer.
Screen
Working in screen allows users to exit the servers without terminating the running processes. Therefore, you should always work in screen when running complex programs that run for longer time. For instructions on how to open and close a screen window, see the ‘Useful server commands’ section below.
Virtual environment
When your code requires specific python packages, you should download them to a virtual environment. The Python environment on the server incorporates only the most basic Python packages so it is always recommended to work in a virtual environment. For instructions on how to create and activate a virtual environment, see the ‘Useful server commands’ section below.
If your program runs from a main.sh file, you can easily automate the creation of the virtual environment by inserting the following script to your code.
Substitute the name of the virtual environment and local package folder (if applicable) appropriately.
virtualenv 'NAME_OF_THE_ENV'
. 'NAME_OF_THE_ENV'/bin/activate
pip install -r requirements.txt
pip install -f 'LOCAL_PACKAGE_FOLDER'/ -r requirements-local.txt
YOUR_CODE
deactivate
To create a virtualenv and use it permanently, one can use mkvirtualenv:
$ mkvirtualenv pandas
(pandas) $ pip install pandas
(pandas) $ python
(pandas) $ deactivate
$ echo "I am no longer in a virtualenv."
$ workon pandas
(pandas) $ pip install jupyter
Parallelization
Parallelization refers to the spreading the code processing work across multiple cores (CPUs). Parallelization is useful to fasten the running time of codes by optimizing the available resources.
For a short introduction on parallelization in Python, please visit the following website: https://sebastianraschka.com/Articles/2014_multiprocessing.html
STATA
You can access the STATA program with graphical user interface on the haflinger. The stata is located in the folders:
/usr/local/stata16/xstata-mp
Python
The servers run both python2 or python3.
You can access them by typing python2 for python2 (current version 2.7.18) and python for python3 (current version 3.8.5).
To leave the python shell and return to the system shell, type the python command exit().
Useful server commands:
| Code | Short description |
|---|---|
htop |
Check servers usage, CPU and memory (see also top) |
screen |
Create screen running in the background. Ctrl-A-D to close the screen, Ctrl-D to shut down (terminate) the screen. |
screen -r "number_of_screen |
Open previously created screen |
virtualenv “name_of_virtualenv” -p python |
Create a Python3 virtual environment |
virtualenv “name_of_virtualenv” -p python2 |
Create a Python2 virtual environment |
. [‘name_of_virtualenv’]/bin/activate |
Activate virtual environment |
pip3 install -r requirements.txt |
Install requirements for virtual environment listed in requirements.txt |
pip3 install -r requirements_packages.txt -f packages/ |
Install every requirement that are contained in a folder (as files) |
pip freeze |
Show downloaded python libraries |
pip freeze -> requirements.txt |
List the currently downloaded python packages |
exit |
Terminate connection with the server |
Contacts
- If you have technical difficulties with the server, please contact a Project Manager.
- For VPN-related problems, please contact CEU HelpDesk at helprequest@ceu.hu.
- If you have a problem with a specific application (e.g., Stata, Matlab), a Project Manager can help you decide whether the problem is with the operating system or with the application. In the latter case, he can put you in touch with Stata or Matlab support.
Key Points
bead: Chaining your data and code together
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How do you ensure that your data products are reproducible?
Objectives
Use
bead, a command-line tool to create, update and share data products.
The problem
Researchers and analysts need to know the provenance of their data to trust its integrity and to quickly redo the analysis when requirements change. However, in a diverse and agile team, knowledge about data is often tacit, and is destroyed when a team member leaves. This leads to a duplication of effort. Additionally, the multitude of software tools and work methods create frictions in the analytics process. Existing solutions are either too rigid to be widely adopted or involve too much face-to-face communication, reducing researcher and analyst productivity.
bead is a lightweight software tool with which a researcher can explicitly declare dependency on other data products, referring to them with a universally unique identifier. She can see how her work fits in the bigger picture and who to work with when redoing the analysis. Bead encapsulates data, the software script that created it and references to its dependencies in a single package, making knowledge about the data explicit. Bead is platform independent and agnostic to the specific software tools and workflows used to create data. It can be adapted to any workflow that uses the file system for both scripts and data. Sample use cases include social and business datasets of a few GB each, processed and analyzed with perl, Python, R, Stata, Matlab, julia or other scripts.
Basic logic of bead
Given a discrete computation of the form
output = function(*inputs)
a BEAD captures all three named parts:
output- data files (results of the computation)function- source code files, that when run hopefully computeoutputfrominputsinputs- are other bead’outputand thus stored as references to those beads
As a special case pure data can be thought of as constant computation having only output but neither inputs nor source code.
Bead concepts
Data packages can be in one of two states. Under active development in a workspace, or packaged and stored as a bead. Beads are stored in a box, which is just a collection of completed beads.
To see how workspaces are created from beads and vice versa, also see usecases
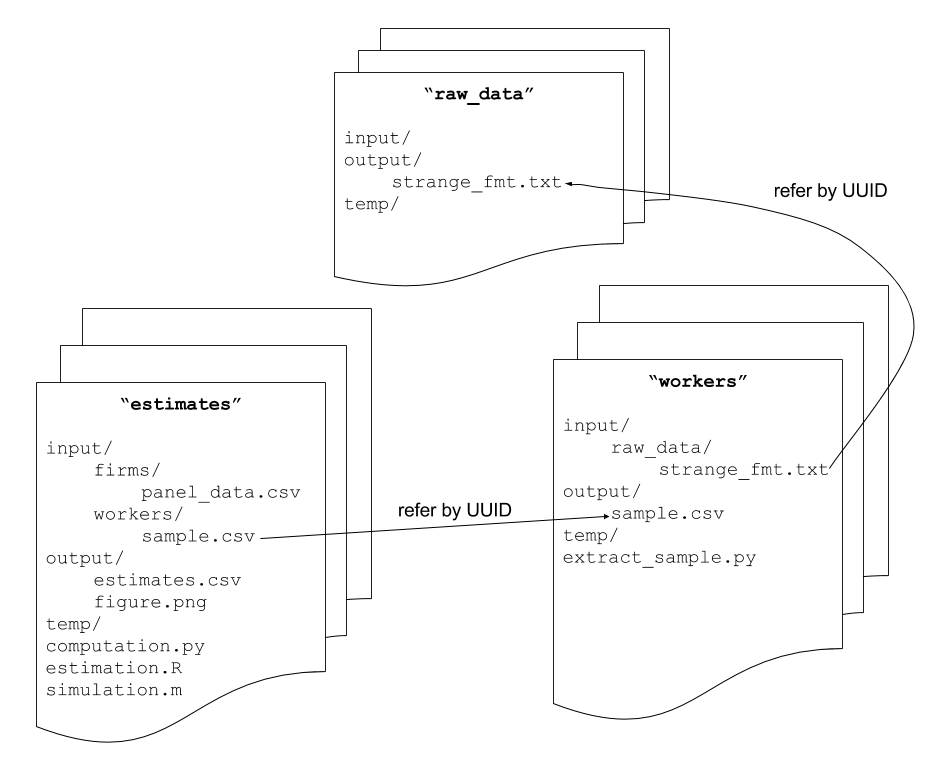
Workspace
A workspace is a directory, where the user works. It contains a prototype of a bead - it is a computation under active development. At some time however it is supposed to have all the inputs, code and output of a computation.
The directory has special structure and content, so it must be created via the bead tool:
- there are metadata in a hidden .bead-meta directory which .txt file enumerate all the inputs and the bead unique hash id.
- there are 3 standard directories with special meanings:
input: where input data is read from. It is read only, managed by thebeadtool.temp: temporary outputs, this is an area that is ignored when saving the bead.output: This is where results of the computation are stored.
Bead
A bead is a frozen, discrete computation, created from a workspace. It is currently a zip file.
A bead is intended to capture data with the code that produced it. The goal is transparency and semi-automatic reproducability through extra tooling. Full automatic reproducability is assumed to be inpractical/expensive, however it can be achieved by gradual process/quality improvements (learning through feedback).
The bead format is designed to be
- resilient to change
- decentralized
- keep enough information to be able to get both the details and the big picture (if all relevant beads are available)
The main technology involved is a combination of different probabilistic identifiers (UUID, secure hash, Merkle-tree).
Main properties of a bead:
kindthat is shared with other versions of a bead (book analogy: ISSN)- it is a technical name, whose existence allows the human name to change/evolve/diverge over time, while still referring to conceptually the same computation
content_id, that is unique for every bead (~version, book analogy: ISBN)- it is calculated, so changes in a bead makes it either invalid or a new version
- freeze time (for ordering versions, this is fragile in theory as depends on correctly set clocks, but in practice it is expected to cause few problems)
- freeze name
- references to its inputs (
kind,content_id)
The main changes from v. 0.0.2. to 0.8.1 that beads are referenced by names from here on.
It is important to mention that we should not create a new bead with a name already in use.
Box
A box is where beads are saved to and loaded from. It also gives names to beads and provide minimal search functionality. Currently, boxes are implemented a flat directories on the file system.
Installing bead
- install python if not already installed. Latest release depends on Python 3.8.5.
- download latest version from https://github.com/e3krisztian/bead/releases/tag/v0.8.1
you will need only the platform specific binary:
beadfor linux & macbead.cmdfor windows
- put the downloaded file in a location, that is on the PATH
for Linux known good locations are:
$HOME/bin(single-user, laptop, desktop, traditional location)$HOME/.local/bin(single-user, laptop, desktop, new XDG standard?)/usr/local/bin(system, servers, multi-user) for windows the python/scripts directory is a good candidate.
- (linux and mac only): make the file executable
For user install, the directories do not exist by default and they are only added to the PATH if exist.
E.g. the following commands would install version v0.8.1 (latest release at the time of writing) on linux:
# ensure user bin directory existst (for user specific scripts)
mkdir -p ~/.local/bin
# download bead
cd ~/.local/bin
wget https://github.com/e3krisztian/bead/releases/download/v0.8.1/bead
# make executable
chmod +x bead
# go back to work directory
cd -
(source: https://stackoverflow.com/c/ceu-microdata/questions/18)
Basic workflow
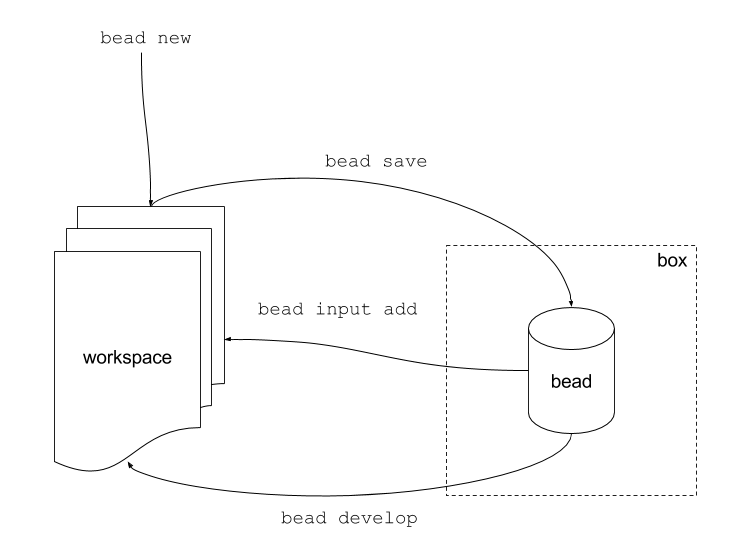
Bead help
The bead help guide you through the usage of the bead.
$ bead -h
usage: bead [-h] {new,develop,save,status,nuke,web,zap,xmeta,version,input,box}
positional arguments:
{new,develop,save,status,nuke,web,zap,xmeta,version,input,box}
new Create and initialize new workspace directory with a new bead.
develop Create workspace from specified bead.
save Save workspace in a box.
status Show workspace information.
nuke No operation, you probably want zap, to delete the workspace.
web Manage/visualize the big picture - connections between beads.
zap Delete workspace.
xmeta eXport eXtended meta attributes to a file next to zip archive.
version Show program version.
input Manage data loaded from other beads...
box Manage bead boxes...
optional arguments:
-h, --help show this help message and exit
All the positional arguments have own subcommands with complete help.
$ bead new -h
usage: bead new [-h] DIRECTORY
Create and initialize new workspace directory with a new bead.
positional arguments:
DIRECTORY bead and directory to create
optional arguments:
-h, --help show this help message and exit
Create a new bead
Initial setup.
The latest bead-box already made on the haflinger.
$ mkdir /somepath/bead-box/latest
$ bead box add latest /somepath/bead-box/latest
Will remember box latest
This is where completed beads will be stored. Create an empty bead with name name:
/somepath$ bead new name
Created name
Add some data to the output of this new bead which we can use later. This bead has no computation, only data.
/somepath$ cd name/
/somepath/name$ echo World > output/who-do-i-greet
/somepath/name$ bead save latest
Successfully stored bead.
cd ..
/somepath/$ bead zap name
Deleted workspace /somepath/name
Working with inputs in a new bead
Create a new data package:
/somepath$ bead new hello
Created hello
/somepath$ cd hello/
Add data from an existing bead at input/<input-name>/:
/somepath/hello$ bead input add name
Loading new data to name ... Done
Create a program greet that produces a greeting, using input/name as an input:
read name < input/name/who-do-i-greet
echo "Hello $name!" > output/greeting
Run the program:
/somepath/hello$ bash greet
This script has create a text file in output/greeting. Let us verify its content:
/somepath/hello$ cat output/greeting
Hello World!
Visually display the bead chain
Bead web is a new feature of version 0.8.1. You can check the details with bead web -h
$ bead web color auto-rewire heads / source-bead target-bead / png filename.png
Auto-rewire is required for the new bead.
Color is optional.
Heads are optional: if loaded they will only plot the latest version of each bead plus what is referenced by another bead.
If you change the source bead to .. it plots the entire bead structure leading to the target bead.
If you change the target bead to .. it plots the entire structure starting from the source bead.
It is very important that before and after / you need a space character.
Instead of png it can be svg filename.svg if you prefer that format.
Package the data and send it to an outside collaborator
Save our new bead:
/somepath/hello$ bead save latest
Successfully stored bead.
This stores output, computation and references to inputs. Now the content of /somepath/BeadBox is
/somepath$ ls -1 BeadBox/
hello_20160527T130218513418+0200.zip
name_20160527T113419427017+0200.zip
These are regular (and, in this case, small) zip files, which can be transferred by usual means (e.g. emailed) to collaborators. The recipient can process them via the bead tool, keep the integrity of provenance information, and adding further dependencies as needed. Even withouth the tool, she can access the data by directly unzipping the file and inspecting its content.
The output of the computation is stored under data/*. An outide collaborator without access to bead can just ignore the computation and all other metadata.
/somepath$ unzip -p BeadBox/hello_20160527T130218513418+0200.zip data/greeting
Hello World!
/somepath$ unzip -v BeadBox/hello_20160527T130218513418+0200.zip
Archive: BeadBox/hello_20160527T130218513418+0200.zip
This file is a BEAD zip archive.
It is a normal zip file that stores a discrete computation of the form
output = code(*inputs)
The archive contains
- inputs as part of metadata file: references (content_id) to other BEADs
- code as files
- output as files
- extra metadata to support
- linking different versions of the same computation
- determining the newest version
- reproducing multi-BEAD computation sequences built by a distributed team
There {is,will be,was} more info about BEADs at
- https://unknot.io
- https://github.com/ceumicrodata/bead
- https://github.com/e3krisztian/bead
----
Length Method Size Cmpr Date Time CRC-32 Name
-------- ------ ------- ---- ---------- ----- -------- ----
13 Defl:N 15 -15% 2016-05-27 13:01 7d14dddd data/greeting
66 Defl:N 58 12% 2016-05-27 13:01 753b9d15 code/greet
742 Defl:N 378 49% 2016-05-27 13:02 a4eb5de9 meta/bead
456 Defl:N 281 38% 2016-05-27 13:02 9a206f53 meta/manifest
-------- ------- --- -------
1277 732 43% 4 files
The following graph summarizes the internal structure of a workspace and the logical links to other beads.
Bead boxes
Key Points
Keep and share data together with the code that produced it.
When sharing your data, always do it in a bead.
Never refer to external data from a bead, use bead inputs.
Key datasets in MicroData
Overview
Teaching: 0 min
Exercises: 0 minQuestions
Which are the most important datasets and how to join them together?
What is an LTS dataset?
Where do I find the datasets on the server?
Objectives
Understand the difference between primary and foreign keys
Get to know major databases
Main datasets
The three main important datasets are the merleg-LTS-2019, the cegjegyzek-LTS-2019 and the procurement-LTS-2019.
The meaning of LTS is long-term support and 2019 is the input year when the data arrived.
The merleg data updates are arriving in December and contains information of the previous tax year. In the 2019 version the last tax year is 2018. The merleg database are processed version of the income statements, the balance sheet (assets and liabilities) and the additional annexes.
The cegjegyzek updates are arriving every year at May and contains information till that date.
LTS
The long-term support database idea comes from software development.
https://en.wikipedia.org/wiki/Long-term_support
Our LTS products will be upgrading every year at a given date. The users can count with the new versions and have enough time to prepare their scripts on them.
Every time when we make a new LTS there is a possibility to add new feature request. Before every version update the team talk trough which feature requests will be in each releases.
Primary keys
The Primary key constraint uniquely identifies each record in a table.
Primary keys must contain UNIQUE values, and cannot contain NULL values.
A table can have only ONE primary key; and in the table, this primary key can consist of single or multiple columns (fields).
https://www.w3schools.com/sql/sql_primarykey.asp
Frame_id
Frame_id is the primary key in most of our datasets represents a unique identifier for each corporation in our data. The unit of observation is an incorporated business entity. Frame_id connects companies transformed from one predecessor to one successor. It is based on registry court columns and announcement information about the transformation of companies. It aims to prolong the life of companies by not breaking the life cycle when a company changes tax number during transformation.
Frame IDs that start with “ft” are created from a tax identifier of the firm. Frame IDs that start with “fc” are created from a cégjegyzékszám. This means that the variable is composed of a notation “ft” and the first tax number in time. Any number could appear after “ft”, the use of the tax_id is left only to help with verification but it is better not to use it as a valid tax number.
Tax_id and originalid
Tax id could be primary or foreign key also.
From the full length 11 character long tax_id we use the prime number the first eight character of the id.
More information about the Hungarian tax ids:
https://hu.wikipedia.org/wiki/Ad%C3%B3sz%C3%A1m
The variable called originalid in merleg database is basically a tax id where we use a fictive negative number if we have a missing tax_id.
In the merleg database we drop the tax_ids starts with 15,16,19 or if they bigger than 3000001.
More about Hungarian tax_id character meanings:
https://drive.google.com/file/d/1mxWv2Pz2bES-5dDo-FUWj83wYJImvOCR/view?usp=sharing
Detailed meta information about the main datasets
merleg-LTS-2019
The detailed variable descriptions and development history are in the merleg-LTS-2019 bead output folder. The most important merleg related variables are the following:
variable name type format variable label
frame_id str15 %15s Frame_id identify one firm. Only_originalid if not valid
originalid long %10.0g Given year Taxid. Minus if taxid not valid
year int %9.0g Year 1980-2018
sales double %12.0g Sales 1000HUF
sales18 double %12.0f Sales in 2018 price 1000HUF
emp double %9.0f Employment clean v2
export double %12.0g Export sales 1000HUF
wbill double %12.0g Wage bill, Bérköltség 1000HUF
persexp double %12.0g Payments to personnel, Szemráf sum 1000HUF
pretax double %12.0g Net profit before taxation 1000HUF
teaor03_2d byte %9.0g 2 digit TEAOR03
teaor08_2d byte %9.0g 2 digit TEAOR08
gdp double %10.0g Gross Value Added: sales+aktivalt-ranyag 1000HUF
gdp2 double %10.0g Gross Value Added:(persexp+kecs+ereduzem+egyebbev)-egyebraf 1000HUF
ppi18 double %10.0g Producer price index 2018=1
so3_with_mo3 byte %9.0g State and local government owned dummy with ultimate owners from Complex
so3 byte %9.0g State government owned dummy with ultimate owners
fo3 byte %8.0g Foreign owned dummy with ultimate owners from Complex
do3 byte %9.0g Domestic owned dummy which is not so3 or fo3
mo3 byte %9.0g Local government owned dummy which is not so3
Cegjegyzek-LTS-2019
Organization of information in files
Entities
In the different relation files contain fields (owner_id, manager_id, frame_id, person_id_1, person_id_2) for entities designated with ids. In manage.csv and own.csv the type field (manager_type, owner_type) containing two-part strings separated with a hyphen, in the first part ‘HU’ stands for hungarian, domestic entity, while the second part designates whether it is a person (‘P’), a firm (‘F’), a municipality owned (‘MO’), a central government owned (‘SO’) or other unspecified (‘O’) type entity. The entity ids can take one of the following form:
Frame ID
See frame_id section.
Person ID
If an ID starts with ‘P’ it uniquely designates a person with hungarian name. If it starts with ‘PP’ the uniqueness is derived from knowing both the own and mother’s name of the person, if it starts with ‘PHM’ the uniqueness is based own husband’s and mother’s name, if it starts with ‘PR’ the uniqueness is based on rarity of the name.
Public owned entity ID
For hungarian public (i.e. state or municipality) owned entities we used the pir id, which is a 6-digit number. The ‘SO001’ stands for state ownership through non specified entity. ‘10011953’ designates the Hungarian National Bank, which has no pir id. The ‘entity/pir.csv’ contains the pir number and the corresponding entity.
Mock ID
If an ID starts with ‘FP’ it is a mock id, which means it is neither a uniquely resoluted person with hungarian name, or a hungarian corporation or a state owned entity. Entities with this ID are unique within but not across corporations.
Address ID
Address IDs are structured like this:
CC-SSSSS-DD-AA-WWWWW-TT-N(NNN)
Where:
- CC: Two-character country code, e.g.: HU
- SSSSS: Settlement code. For Hungarian addresses this is the KSH Code.
- DD: District. For Budapest the actual district, 00 if unknown. For cities with suburbs it should be 01 for the city itself, and 02, 03, 04 etc. for the different suburbs.
- AA: Larger administrative area (county, only for hungarian addresses)
- WWWWW: Public way name. The same name should have the same ID across settlements.
- TT: Public way type/Street suffix. The same type should have the same ID across settlements. The key for this is in entity/official_domain_names.csv
- N(NNN): The number of the building. If a building has a span of numbers, the lowest should be used. E.g. in case of Nador utca 9-15, number 9 is to be used.
For now, we don’t identify floors and door numbers.
Direct relations
Direct relations are relations explicitly available in Corporate Registry. In these files the ‘source’ field contains a 4 part string separated by underscores designating the reference to the original CR data point, the 4 parts are the following: CR number (cégjegyzékszám), CR rubric (rovat), row number within rubric (alrovat_id) and the group prefix (the prefix of variable group within rubric row: ‘’, ‘p’, ‘pc’, etc.)
ownership - relation/own.csv
The table contains the ownership relations as they are documented in Corporate Registry. The entity designated with ‘owner_id’ is an owner in a hungarian corporation designated with the frame_id. The ‘owner_id’ can take a form of a person_id, frame_id or a tax_id of a state or municipality owned entity. The ‘share’ field is a ratio which shows the realtive share of the owner entity in the corporation. The ‘share_flag’ tells us about the quality of the data (empty string - no share data was avaialble, 0.0 - could not be tested against share emission data, 1 - total share counts add up to share emission data, 2.1-2.2 the share was corrected using emission data, 3 - messy share data). The ‘share_source’ indicates from which original data field the share comes from.
signature rights and board members - relation/manage.csv
This table contains the significant employees and board members (‘manager_id’) for a specific corporation (‘frame_id’). The data comes from rubric 13 (signature rigths) and 15 (board members) of the Corporate Registry. The ‘position’, ‘board’, ‘liquidator’, ‘self-liquidator’ fields designate the role played by the entity within the corporation. The ‘position’ field can be one of the following values: ‘1’ - CEO, ‘2’ - significant manager, 3 - other employee, 0 - no specific information.
Indirect relations
Firm and person networks based on ownership and location
The outputs are temporal edge lists. Each record in the output csv files contains an edge. Each record contains the nodes connected by the edge along with the beginning date and end date of the connection and the shared characteristic between the two nodes. If the end date of the connection is empty it means that the connection is still in effect. A network file may contain flags describing the type of connection. These flags are described below at the corresponding network. The code currently generates the following three network types:
Firm network based on common owner or manager
Two firms (identified by frame id) are connected if they share an entity (manager or owner, identified by manager_id or owner_id) at a given time period. The output contains mixed connections (i.e. person X is a manager at firm A and an owner of firm B at a given time period). The role of the person (or entity, an owner may be a firm for example) in the two firms is conserved by corresponding position variables taking the values “o” for owner and “m” for manager. If you need a network based on only ownership connections you can easily filter this output to those edges where both position variables take the value “o”. The same way it works for a manager based network.
Person network based on common firm
Two people (identified by manager_id or owner_id, but ONLY IF it is a proper person id) are connected if they are present at the same firm (as a manager or owner) at a given time period. The output contains mixed connections (i.e. person A is a manager at firm X while person B is an owner of firm X at a given time period). The roles of the people in the firm are conserved by corresponding position variables taking the values “o” for owner and “m” for manager.
Firm network based on common address
Two firms (identified by frame id) are connected if they share an address (hq, site or branch, identified by address_id) at a given time period. The output contains mixed connections (i.e. Firm A has it’s HQ at address X and Firm B has a branch at the same location). The role of the address in the two firms is conserved by corresponding type variables taking the values “h” for HQ, “b” for branch, and “s” for site.
## Schema
####entity/county_settlement.csv
settlement
county_code
####entity/HU-TTT.csv
pw_type
index
timestamp
####entity/official_domain_names.csv
Names
####entity/HU-WWWWW.csv
pw_name
index
timestamp
####entity/settlement_codes.csv
settlement
suburb
SSSSS
DD
####entity/county_codes.csv
irsz
county_code
####entity/pir.csv
pir
tax_id
name
settlement
####entity/frame.csv
frame_id
tax_id
ceg_id
name
is_alive
birth_date
death_date
is_hq_change
is_site
is_transforming
is_in_complex
is_tax_id_corrected
####relation/manage.csv
frame_id
source
manager_id
manager_type
sex
birth_year
valid_from
valid_till
consistent
address_id
country_code
board
position
self_liquidator
liquidator
####relation/own.csv
frame_id
source
owner_id
owner_type
sex
birth_year
valid_from
valid_till
consistent
address_id
country
share
share_flag
share_source
####relation/hq.csv
frame_id
address_id
source
valid_from
valid_till
####relation/site.csv
frame_id
address_id
source
valid_from
valid_till
####relation/branch.csv
frame_id
address_id
source
valid_from
valid_till
####relation/firm_network_common_owner.csv
edge_id
frame_id_1
frame_id_2
pos_1
pos_2
valid_from
valid_till
####relation/owner_network_common_firm.csv
edge_id
person_id_1
person_id_2
pos_1
pos_2
valid_from
valid_till
####relation/firm_network_common_address.csv
edge_id
frame_id_1
frame_id_2
type_1
type_2
valid_from
valid_till
Procurement-LTS-2019
The bead chain
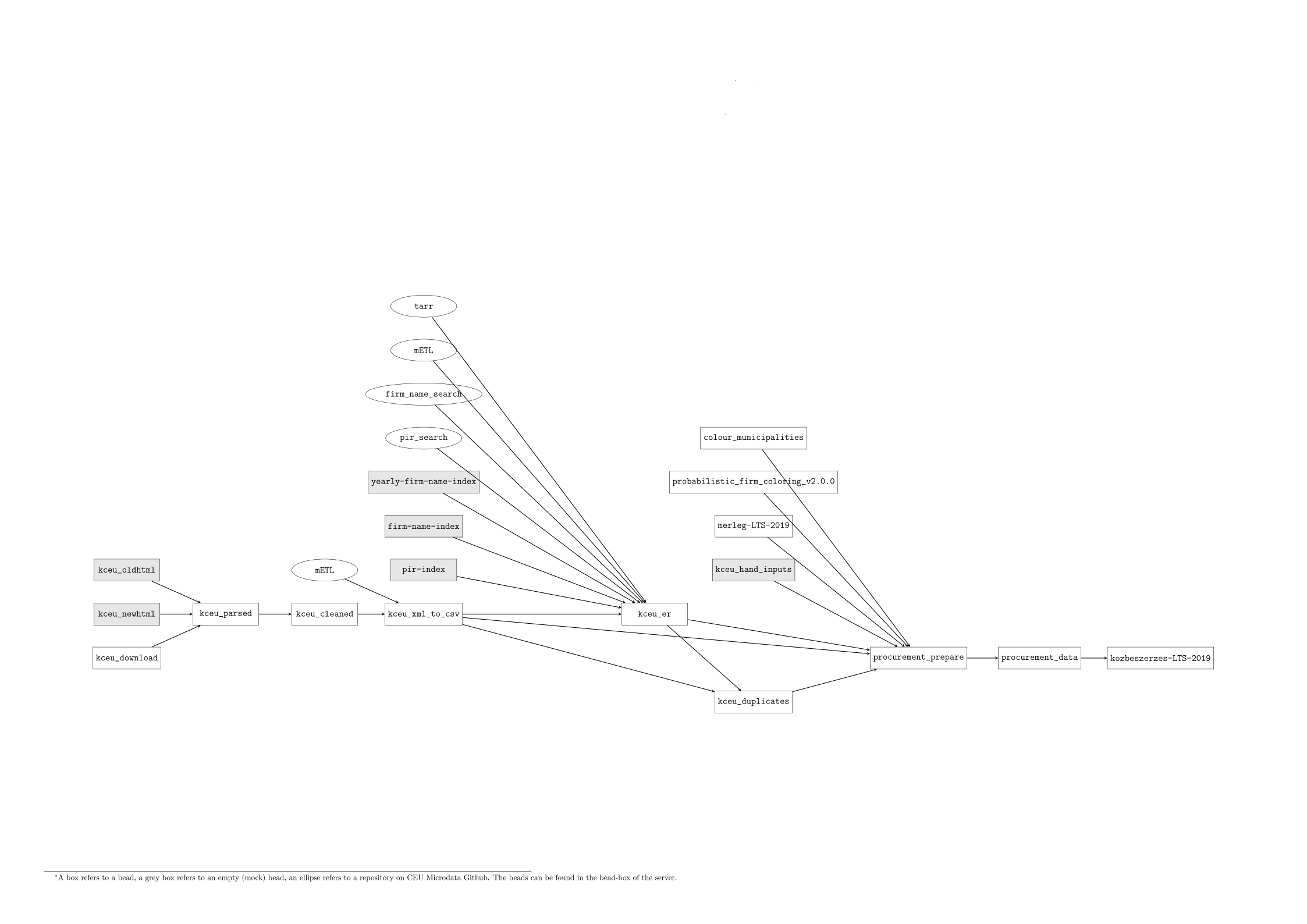
The input data is from the Procurement Authority website http://www.kozbeszerzes.hu. The final bead is the kozbeszerzes-LTS-2019.
The bead chain is made up of these elements:
-
kceu_oldhtml: Mock bead (output only). Contains tenders between 1997 and 2006. These files cannot be retrieved from the website anymore. The files are in html format in the output folder. -
kceu_newhtml: Mock bead (output only). Contains tenders between 2007 and 2017. These files have been downloaded by the scripts of thekceu_downloadbead (see below). The files are in html format in the output folder. -
kceu_download: Contains scripts for downloading tenders from the website for any arbitrary year. Currently it contains the 2018 tenders. The files are in html format in the output folder. -
kceu_parsed: Using the three above beads as input, it converts the tender html files to structured, hierarchical xml files by extracting the relevant pieces of information from the published notices. This bead mainly consists of an external parser and the modular parser. The external parser software works as a black box for us. The latter is an internal development which works for certain notice types, to improve the external parser performance. The output files are structured xml files for each tender. -
kceu_cleaned: Using thekceu_parsedbead as input, it removes empty tags from the xml files, and converts foreign currencies to HUF. -
kceu_xml_to_csv: Using thekceu_cleanedbead as input, it converts the xml (separate files for each tender) to different csv files. These arepart.csvwhich contains the basic information of the tenders (subject, cpv, value, etc.),requestor.csv,bidder.csv, and thewinner.csv, which list the relevant entities for each tender part. Note that the latter are intermediary products in the sense that entity resolution and deduplication is still to be carried out on these files (see below). -
kceu_er: Using the csv files of thekceu_xml_to_csvbead (and additional beads of firm and pir name indexes) as input, it applies entity resolution on the tenders (usingpir search toolandfirm name search tooldeveloped within Microdata): that is, it tries to identify the bidder, winner, and requestor firms and institutions using our databases at Microdata. The outputs are the resolved winner, bidder, and requestor csv files which will contain unique identifier (tax id or pir id) for entities so that it can be merged with another Microdata products. -
kceu_duplicates: Using thepart.csvfrom thekceu_xml_to_csvbead, and the resolved csv files of thekceu_erbeads, it identifies duplicate tenders. It is necessary because some tender result are announced multiple times at the official website for some reason (this is more frequent for older tenders). The identification is based on similarity of requestors and bidders, subject, value, and decision date. The output is aduplicates.csvfile which list the duplicate tender ids and indicates which lines to drop and which to keep. -
kceu_hand_inputs: Despite all our effort to convert every existing procurement data creation process into beads to guarantee reproducibility, there are some remaining files for which we could not identify the source code and/or are unique hand collected inputs that do not fit into standard bead structure. The output files of this empty bead serve as inputs for theprocurement_preparebead. -
procurement_prepare: This bead combines the output files ofkceu_xml_to_csv,kceu_er,kceu_duplicates, and generates a tender part – bidder level datafile (all_bids.dta). Moreover, using mostlymerleg-LTS-2019and some other inputs such as probabilistic firm coloring, it prepares some auxiliary files which contain information on firms, pir entities, firms political connections, and election results. -
procurement_data: This bead builds solely upon the input files prepared in theprocurement_preparebead. Combining these files, it produces two types of output data ready for analysis: a tender – bidder level dataset calledprocurement_bids_data, which contains all the necessary information from the tender (subject, cpv, estimated value, final value, etc.), the requestor and bidder entities (location, NACE code, balance information, etc.), as well as the outcome of the tender.procurement_wins_datais essentially the same file, but for each tender only the winning bidders are included. The other type of output data calledgovernment_private_sales_datais a yearly panel of firms. Besides the most important balance information, it is a yearly aggregate of each firm’s procurement revenues, and based this the private revenues are also derived.
Media and scraped datasets
We have scraped, parsed and cleaned version of the biggest online media providers in the media-bead-box
We have firm year month unique information about advertisement data from 1991-2016.
Key Points
LTS dataset is supported in the same format at every update
LTS beads are more than just a bunch of beads: one LTS package is suitable for use in a large variety of research trends
How to work with the data
Overview
Teaching: 0 min
Exercises: 0 minQuestions
What are the general rules about working with data?
How to handle sensitive data?
Objectives
Distinguish data at different stages of processing.
Protect sensitive data with appropriate measures.
Stages of data
Stage 0: raw data
Raw data is incoming data in whatever format. HTMLs scraped from the web, a large SQL dump from a data vendor, dBase files copied from a 200 DVDs (true story). Always store this for archival and replication purposes. This data is immutable, will be written once and read many times.
Example: country names, capitals, areas and populations scraped from scrapethissite.com, stored as a single HTML file.
Stage 1: consistent data
Constistent data has the same information content as the raw data, but is in a preferred format with a consistent schema. You can harmonize inconsistent column names, correct missing value encodings, convert to CSV, that sort of thing. No judgmental cleaning yet. In our case, consistent data contains a handful of UTF-8 encoded CSV files with meaningful column and table names, generally following tidy data principles. The conversion involves no or minimal information loss.
Example: A single CSV file with columns
country_name,capital,area,population, in UTF-8 encoding.
Stage 2: clean data
Clean data is the best possible representation of information in the data in a way that can be reused in many applications. This conversion step involves substantial amount of cleaning, internal and external consistency checks. Some information loss can occur. Written a few times, read many times, frequently by many users for many different projects. When known entities are mentioned (firms, cities, agencies, individuals, countries), they should be referred to by canonical unique identifiers, such as ISO-3166–1 codes for countries.
Example: Same as consistent, with additional columns for ISO-3166 code of countries and geonames ID of cities. You can also add geocoordinates of each capital city.
Stage 3: derived data
Derived data usually contains only a subset of the information in the original data, but is built to be reused in different projects. You can aggregate to yearly frequency, select only a subset of columns, that sort of thing. Think SELECT, WHERE, GROUP BY clauses.
Example: All countries in Europe.
Stage 4: analysis sample
Analysis sample contains all the variable definitions and sample limitations you need for your analysis. This data is typically only used in one project. You should only do JOINS with other clean or derived datasets at this stage, not before. This is written and read frequently by a small number of users.
Example: The European country sample joined with population of capital cities (from the UN) so that you can calculate what fraction of population lives in the capital.
How do you progress from one stage to the other?
Automate all the data cleaning and transformation between stages. This is often hardest between raw and consistent, what with the different formats raw data can be in. But from the consistent stage onwards, you really have no excuse not to automate. Have a better algorithm to deduplicate company names (in the clean stage)? Just rerun all the later scripts.
Don’t skip a stage. Much as with the five stages of grief, you have to go through all the stages to be at peace with your data in the long run. With exceptionally nicely formatted raw data, you may go directly to clean, but never skip any of the later stages. This follows from modular thinking: separate out whatever you or others can reuse later. What if you want to redo your country-capital analysis for Asian countries? If you write one huge script to go from your raw data to the analysis sample, none if it will be reused.
Join late. It may be tempting to join your city information to the country-capital dataset early. But you don’t know what other users will need the data for. And you don’t want to join before your own data is clean enough. A clean data should be as close to the third normal form as possible.
Share your intermediate data products. All the data cleaning you have done might be useful for others, too. If possible, share your intermediate products with other analysts by saving a (bead)[FIXME: ref].
Categories of data protection
Privacy and ethical considerations necessitate good data protection practices. We have three categories of data:
CAT1: Public data
The data is available publicly elsewhere. There is no embarrassment if accidentally made public.
There are no restrictions on storage and sharing beyond common sense. Can be shared in response to a data request without approval.
CAT2: Private data
The data is not available publicly. It is proprietary or has business value. (For example, company names, addresses and financials.) Some embarrassment and possible legal implications if accidentally made public.
Access is limited to authorized individuals within CEU. Special care should be taken when sharing, transporting data. Sharing outside CEU may be allowed, but decided on a case-by-case basis.
CAT3: Sensitive data
The data is not available publicly. It either has large business value or relates to sensitive information on individuals specifically protected by GDPR. (For example, addresses of individuals, political connections, names of company partners.) Major embarrassment and certain legal implications if accidentally made public.
Access is limited to authorized individuals within CEU. Data can only be stored and transported on encrypted medium. Sharing outside CEU may be allowed, but decided on a case-by-case basis and encryption rules still apply.
Key Points
Never modify raw data.
Always keep CAT3 data on encrypted medium.
Tools in MicroData
Overview
Teaching: 0 min
Exercises: 0 minQuestions
What is a programing tool and why we use them?
How to read a tool manual and understand the outputs?
Objectives
Join a unique ID to a raw .csv with different input types
Choose the right cut offs and specify the good matches
Get to know how to run a tool on the server with good options
The problem
There are lots of occasions when we would like to automate some tasks by the help of programming tools.
https://en.wikipedia.org/wiki/Programming_tool
One task is when we want to add a unique ID to a raw input variable. An input data could be firm name, person name, governmental institution, foundation, association .etc. Firm and person names also could be foreign ones.
We are continuously developing tools to identify these inputs and give a unique ID to them.
Firm name search tool
Firm name search tool merges the eight-digit registration number (first 8 digits of tax number) to a Hungarian firm name. You can find, among others, the building and installing methods on github:
https://github.com/ceumicrodata/firm_name_search
Using the tool
Requirements:
- Python2 and the tool must be available on the PATH
- a proprietary database index file (available only to members of CEU MicroData)
name-to-taxids-YYYY-MM-DD "firm name" input.csv output.csv
where “firm name” is the field name for firm name in input.csv and there is an index file in the current directory with name complex_firms.sqlite.
The tool provides command line help, so for further details run
name-to-taxids-YYYY-MM-DD -h
FirmFinder.find_complex() expects a single unicode firm name parameter which it will resolve to a match object with at least these attributes:
org_scoretext_scorefound_nametax_id
An example how to run firm name search tool in python2
$ python name-to-taxids-20161004 name temp/distinct_firms.csv temp/distinct_firms_fname.csv --index 'input/firm-name-index/complex_firms.sqlite'
The tool searches for tax numbers for items in the name field.
You must have to add the whitelist path manually: 'input/firm-name-index/complex_firms.sqlite'
The meaning of the outcome and how to choose the proper cut off scores
The tool outcomes and scoring system are based on Hungarian legal forms. If an input data has a valid legal form then more likely a Hungarian company that not.
https://www.ksh.hu/gfo_eng_menu
A good match is dependend on how well prepared the input data is.
If the data pre-filtering is good, before we run the tool, a text_score with lower value could become a good hit.
Good cleaning opportunity to drop person names and foreign firm names from the input data.
Score meaning
org_score text_score meaning
-20 -20 No results.
-10 -10 Too much results.
-1 0 <= x < 1 The legal form doesn’t match, but the input and found names have one.
-1 1 The firm name matches but the legal form doesn’t match.
0 0 <= x < 1 Only the input data have legal form. (Input misspelling error)
0 1 Only the input data have legal form but the firm name matches.
1 0 <= x < 1 Only the found name have legal form.
1 1 In the input data NO legal form but the firm name matches.
2 0 <= x < 1 The legal forms are matching but the firm names not.
2 1 Perfect match.
Can be said generally that most of the possible matches will be in org_score==2 and text_score 0 <= x < 1 category.
If a data is well prepared 0.8 org_score could be a suggested cut-off score. Results above this are expected to be good.
You must have to adjust the good match cut offs in every time in every category when you run the tool on a new input.
PIR name search tool
Pir name search tool is developed for identify Hungarian state organizations by name. Pir number is the registration number of budgetary institutions in the Financial Information System at Hungarian State Treasury.
TIP:
There is an online platform to find PIR numbers one by one.
http://www.allamkincstar.gov.hu/hu/ext/torzskonyv
The PIR search command line tool requires Python 3.6+.
Input: utf-8 encoded CSV file Output: utf-8 encoded CSV file, same fields as in input with additional fields for “official data”
https://github.com/ceumicrodata/pir_search/releases/tag/v0.8.0
This release is the first, that requires an external index file to work with. You can find this index.json file in the pir-index beads. The index file was separated, because it enables match quality to improve without new releases.
The match precision can be greatly improved by providing optional extra information besides organization name:
- settlement
- date
An extra tuning parameter is introduced with –idf-shift which tweaks the matcher’s sensitivity to rare trigrams. Its default value might not be optimal, it changes match quality. Attached files are binary releases for all 3 major platforms: pir_search.cmd is for Windows, pir_search (without extension) is for unix-like systems (e.g. Linux and Mac)
An example how to run pir name search tool in python3
Run from python3 with settlement option
python3 pir_search-0.8.0 input/pir-index/index.json name temp/distinct_firms.csv temp/distinct_firms_pname.csv --settlement settlement --hun-stop-words \
--pir pir_d --score pir_score_d --match_error pir_err_d --taxid pir_taxid_d --pir-settlement pir_settlement_d \
--name pir_name_d --keep-ambiguous
Run from python3 with settlement option and idf-shift 100 and extramatches
python3 pir_search-0.8.0 input/pir-index/index.json name temp/distinct_firms.csv temp/distinct_firms_pname_extra.csv--settlement settlement --hun-stop-words \
--idf-shift 100 --extramatches
The pir_score output could be between 0 <= x < 1. Pir_score==1 AND pir_err==0 is the perfect match.
The bigger the pir_err score the match is more likely wrong.
Pir score bigger than 0.8 and pir_err<0.8 are potentially good matches.
You must have to adjust the good match cut offs in every category, every time when you run the tool on a new input.
Complexweb
Complexweb is and internal searchable version of the raw Complex Registry Court database. VPN and password is required to log in.
TIP:
You can find downloadable official balance and income statements from e-beszámolo.hu:
https://e-beszamolo.im.gov.hu/oldal/kezdolap
You can easily find the firm you are searching for if you change the tax_id or the ceg_id in the html:
Example pages with fictive tax_id
http://complexweb.microdata.servers.ceu.hu/cegs_by_tax_id/12345678 to
http://complexweb.microdata.servers.ceu.hu/cegs_by_tax_id/12345679
Example pages by ceg_id
http://complexweb.microdata.servers.ceu.hu/ceg/0101234567 to
http://complexweb.microdata.servers.ceu.hu/ceg/0101234568
You can write Postgre SQL queries to request more complex searches:
https://www.postgresql.org/docs/13/index.html
Examples
* Count not null ceg_id from rovat 109 which is KFT
select count(distinct(ceg_id)) from rovat_109-- where cgjsz is not null
* Select a string part from a rovat
select * from rovat_99 where szoveg like '%%Összeolvadás%%'
select ceg_id from rovat_3 where nev like '%%nyrt%%' or nev like '%%NYRT%%' or nev like '%%Nyrt%%'
* Select a string part from a rovat order and limit
select ceg_id from rovat_99 where szoveg like '%%átalakulás%%' and szoveg not like '%%való átalakulását határozta el%%' order by random() limit 20
* Select different variables from different rovats with join.
where a tax_id is xxx
AND létszám is xxx or datum is somethin
-- means that line is not executing
-- explain
SELECT ceg_id, letsz, rovat_0.adosz, nev, datum, tkod08 -- *
FROM
rovat_0
join rovat_99003 using (ceg_id)
join rovat_99018 using (ceg_id)
join rovat_8 using (ceg_id)
where
-- rovat_0.adosz like '11502583%%'
-- rovat_0.adosz like '1150%%'
-- rovat_99003.letsz ~ '^(1[1-5]|23)$'
rovat_99003.letsz ~ '^13..$'
AND rovat_8.alrovat_id = 1
AND left(coalesce(rovat_8.datum, ''), 4) = '2006'
AND rovat_99018.tkod08 like '77%%'
* Select rovats and join by ceg_id by the help of with
-- explain
with
all_firms as (select left(adosz, 8) taxid8, ceg_id from rovat_0),
more_than_one_ceg as (select taxid8 from all_firms group by taxid8 having count(*) > 1),
ignored_taxid8 as (select distinct taxid8 from more_than_one_ceg join all_firms using (taxid8) join rovat_93 using (ceg_id)),
hirdetmeny as (select distinct taxid8 from more_than_one_ceg join all_firms using (taxid8) join rovat_99 using (ceg_id))
(select taxid8 from more_than_one_ceg) intersect (select taxid8 from hirdetmeny) except (select taxid8 from ignored_taxid8 )
limit 10
;
Time machine tool
A tool for collapsing start and end dates and imputing missing dates.
https://github.com/ceumicrodata/time-machine
Make a new environment to run the tool
virtualenv -p python3 env
. env/bin/activate
Required files:
You need these .py files to your code folder to run the tool:
- timemachine.py
- timemachine_mp.py
- timemachine_tools.py
Required inputs:
-
An entity resolved csv file. Example: complex rovat csv files with person IDs.
-
Rovat 8 csv file, which contains the birth dates of firms.
-
Frame, which contains the death date of firms in the death_date column.
Usage: timemachine.py [-h] [-s START] [-e END] [-u] entity_resolved rovat_8 deaths order unique_id is_sorted fp out_path
Optional arguments:
-
-h: Shows a help message and exits.
-
-s START: Comma separated field preference list for start dates. e.g. hattol,valtk,bkelt. DEFAULT: hattol,valtk,bkelt,jogvk
-
-e END: Comma separated field preference list for end dates. e.g. hatig,valtv,tkelt. DEFAULT: hatig,valtv,tkelt,jogvv
-
-u: Unique flag. Should be used if only a single entry is valid at any given time.
Positional arguments:
-
entity_resolved: The path to the entity resolved input csv file.
-
rovat_8: The path to the rovat 8 csv file.
-
deaths: The path to the frame.
-
order: A column of the entity resolved csv file describing the order of records within a firm. It is usually the alrovat_id.
-
unique_id: A column of the entity resolved csv file which contains unique entity IDs. E.g.: person ID
-
fp: A comma separated list of column labels in the entity resolved csv file describing the path to a single firm. It is usually ceg_id.
-
out_path: Path where the output should be written.
An example how to run time machine tool on the server
In this example we would like to clean the raw NACE input dates by ceg_id:
$ python3 timemachine_mp.py -u temp/rovat_902_fortm_fotev.csv input/frame-20190508/frame_with_dates.csv alrovat_id teaor ceg_id temp/rovat_902_tm.csv 25
You can see the -u unique option means that we have one NACE main activity code at the same time.
The unique column is the teaor and the code is using the frame_with_dates.csv which identify one frame_id-tax_id pair for each firm.
The 25 means that we choose multiprocessing with maximum 25 cores.
Key Points
Tools are helping you to automate tasks like joining unique ID-s for an input variable.
Firm name tool good for firm matching and PIR tool is good for state organizations matching
Best practices
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How to name files and variables?
What code style do we use?
How to ensure reproducible research?
Objectives
Use verbose, helpful file and variable names.
Read and write data in a way facilitating reproducibility.
These guidelines help us share data among themselves. Always make the extra effort to make your work understandable to others: you are in the best position to explain what you did. If you follow these guidelines, you only have to do this once for every data product you create.
Naming files and folders
/data/source-of-data/name-of-dataset/stage. For example,/data/mak/pir_entities/raw- Use long, expressive filenames, e.g.
balance-sheet-with-frame.dtarather thanbs-merge.dta - Use-dash-for-word-separation, not CamelCase, space or underscore.
- Do not indicate version in filename. File versions should be managed by version control tool.
- Do not indicate author in filename. File versions should be managed by version control tool.
- For folders and files containing multiples of the same entity, use plain English singular filenames, e.g.
city.csv,county.csv,mayor.csv,exhibit/figure,output/table
Data format
- All text data files use UTF-8 encoding from the “consistent” stage upward. If the raw file is in any other encoding, your first task is to convert it to UTF-8.
- CSV files are generally the preferred format, with
,as separator and”as quote character. Do NOT use;or tab as separator. CSV format is easily processed by all software (Python, STATA, Excel, …), the only problem being with separators and quote characters defined according to individual preferences. - Missing values are missing. Do not include any special values (N/A, -99, 0) for missing values in fields, leave them blank. The user of the data should build in any logic to deal with missing values.
- Only share one format of a dataset. Do not include both .csv and .dta. In some cases, .dta might be preferred (mostly numerical variables, labeling). Then we do not need .csv with the same content.
Input and output
- Every output you are sharing is a file saved by a script. Do not copy paste figures and tables. If you want to share it, create a script that saves it in a file (.dta, .csv, .gph, .pdf, .png etc)
- Every script produces exactly one output, not more. If your code is producing more pieces of output, break it up into smaller pieces.
- Use relative paths exclusively for accessing data.
../data/election/mayor.csv, not/home/koren/projects/political_connections/data/election/mayor.csv - Use forward slashes in paths. (See http://momentofmethods.com/blog/2012/09/19/cultivate-your-tree/)
- The output of a script should be named differently than any existing input or output file generated by other scripts. This rule ensures that the question “what script created this file?” can be answered.
- As a special case: never use the same file for input and output within a single script. If the script fails, nobody will know what the file actually contains.
- Leave no trace: use temporary files and variables. For Stata variables and files storing intermediate calculations, that are not inputs to other scripts, use “tempvar” and “tempfile.” These are automatically deleted once your script finished.
- Only put those data files in output folder of bead that will be actually used. Keep temporary files in the temp folder.
Code style guide
- Python code must follow PEP-8.
- Stata code must follow this guide.
- Stata code should be no longer than 120 lines. If longer, break it up.
Key Points
Name variables and datasets with nouns of what they contain.
Name scripts with verbs of what they do.
Every piece of data is written by a script.
Every piece of data is written by one script.
Stata style guide
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How to name variables?
What code style do we use?
Objectives
Use verbose, helpful variable names.
Make your code accessible to others.
Files
Use forward slash in path names
Write
save "data/worker.dta", not. The former works on all three major platforms, the latter omnly on Windows.save "data\worker.dta
Write out file extensions
Write
save "data/worker.dta"anddo "regression.do", notorsave "data/worker. Even though some extensions are appended by Stata by default, it is better to be explicit to help future readers of your code.do "regression"
Put file paths in quotes
Write
save "data/worker.dta"anddo "regression.do", notorsave data/worker.dta. Both are correct, but the first is more readable, as most editors readily highlight strings as separate from programming statements.do regression
Use relative path whenever possible
Write
save "../data/worker.dta", not. Nobody else will have the same absolute path as you have on your system. Adopt a convention of where you are running scripts from and make paths relative to that location.save "/Users/koren/Tresorit/research/data/worker.dta
Naming
Do not abbreviate commands
Use
generate ln_wage = ln(wage)andsummarize ln_wage, detail, notorg ln_wage = ln(wage). Both will work, because Stata allows you abbreviation, but the former is more readable.su ln_wage, d
Do not abbreviate variable names
Use
summarize ln_wage, detail, not. Both will work, because Stata allows you abbreviation, but the latter is very error prone. In fact, you can turn off variable name abbreviation withsumarize ln_w, detailset varabbrev off, permanent.
Use verbose names to the extent possible
Use
egen mean_male_wage = mean(wage) if gender == "male", not. Your variables should be self documenting. Reserve variable labeling to even more verbose explanations, including units:egen w1 = mean(wage) if gender == "male"label variable mean_male_wage "Average wage of male workers (2011 HUF)".
Separate name components with underscore
Use
egen mean_male_wage = mean(wage) if gender == "male", notoregen meanmalewage = mean(wage) if gender == "male". The former is more readable. Transformations like mean, log should be part of the variable name.egen meanMaleWage = mean(wage) if gender == "male"
Do not put units and time in the variable name
Use
revenue, notorrevenue_USD. Record this information in variable labels, though. You will change your code and your data and you don’t want this detail to ruin your entire code.revenue_2017
It is ok to use short macro names in short code
If you have a
foreachloop with a few lines of code, it is fine to use a one-character variable name for indexing:foreach X of variable wage mean_male_wage {. But if you have longer code andXwould pop up multiple times, give it a more verbose name.
It is ok to use obvious abbreviation in variable names
If you are hard pressed against the 32-character limit of variable name length, use abbreviation that will be obvious to everyone seeing the code. Use
generate num_customer, notorgenerate number_of_customers_of_the_firm.generate n_cust
White space
Include a space around all binary operators
Use
generate ln_wage = ln(wage)andcount if gender == "male", notorgenerate ln_wage=ln(wage). The former is more readable.count if gender=="male"
Include a space after commas in function calls
Use
assert inlist(gender, "male", "female")not. The former is more readable.assert inlist(gender,"male","female")
Indent code that belongs together
foreach X of variable wage mean_male_wage { summarize `X', detail scalar `X'_median = r(p50) }not
foreach X of variable wage mean_male_wage { summarize `X', detail scalar `X'_median = r(p50) }
Each .do file should be shorter than 120 lines
Longer scripts are much more difficult to read and understand by others. If your script is longer, break it up into smaller components by creating several .do files and calling them.
Key Points
How to use csvkit
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How to open data with csvkit?
How to select certain rows and columns of the data? How to append them after filtering?
How to sort and describe basic characteristics of the data?
Objectives
Learn how to install csvkit and how to use csvlook
Learn csvgrep, csvcut and csvstack commands
Learn csvsort and csvstat commands
The use of csvkit
csvkit is a command-line tool written in Python to be used for simple data wrangling and analysis tasks. This tutorial presents the most important commands implemented in it. The following sections rely heavily on the official csvkit tutorial.
Installing csvkit
The csvkit tool can be installed with the following command (if you use Python 2.7 you might type sudo pip install csvkit instead).
$ sudo pip3 install csvkit
For illustration purposes an example dataset is also used in this tutorial. The data contain information on cars and their characteristics. To get the data you should type the following command.
The dataset has a second row with information on data type that is removed for later analysis purposes with the head and tail commands - an alternative way to do this is by using sed 2,2d cars.csv > cars-tutorial.csv.
$ wget https://perso.telecom-paristech.fr/eagan/class/igr204/data/cars.csv
$ head -1 cars.csv > cars-tutorial.csv
$ tail -n+3 cars.csv >> cars-tutorial.csv
The most important csvkit commands
The example dataset is semi-colon and not comma separated. For all the commands presented below the input delimiter can be set with the -d argument: in this case as -d ";". Setting the input delimiter with -d changes the decimal separator in the ouput as well. To change it back to dot from comma, csvformat -D "." should be used after any command where it is relevant.
-
csvlookshows the data in a Markdown-compatible format.catmay also be used instead ofcsvlookto open a csv file, but the latter is more readable. This command can be combined withheadin order to have a look at the first few lines of the data. As seen here and in later examples, csvkit commands can be piped together and with other commands.$ csvlook -d ";" cars-tutorial.csv | csvformat -D "." $ head -5 cars-tutorial.csv | csvlook -d ";" | csvformat -D "."For the latter command the following output can be seen.
| Car | MPG | Cylinders | Displacement | Horsepower | Weight | Acceleration | Model | Origin | | ------------------------- | --- | --------- | ------------ | ---------- | ------ | ------------ | ----- | ------ | | Chevrolet Chevelle Malibu | 18 | 8 | 307 | 130 | 3 504 | 12.0 | 70 | US | | Buick Skylark 320 | 15 | 8 | 350 | 165 | 3 693 | 11.5 | 70 | US | | Plymouth Satellite | 18 | 8 | 318 | 150 | 3 436 | 11.0 | 70 | US | | AMC Rebel SST | 16 | 8 | 304 | 150 | 3 433 | 12.0 | 70 | US | -
csvcutshows the column names in the data if the-nargument is specified. It can also help to select certain columns of the data with the-cargument and the corresponding column numbers (or names).$ csvcut -n -d ";" cars-tutorial.csvThe output is the following:
1: Car 2: MPG 3: Cylinders 4: Displacement 5: Horsepower 6: Weight 7: Acceleration 8: Model 9: OriginThe following two commands have identical outputs: car, miles per gallon consumption and origin columns, as shown below. For space constraints only the first few rows are printed out.
$ csvcut -c 1,2,9 -d ";" cars-tutorial.csv | head -5 | csvlook $ csvcut -c Car,MPG,Origin -d ";" cars-tutorial.csv | head -5 | csvlook| Car | MPG | Origin | | ------------------------- | --- | ------ | | Chevrolet Chevelle Malibu | 18 | US | | Buick Skylark 320 | 15 | US | | Plymouth Satellite | 18 | US | | AMC Rebel SST | 16 | US | -
csvstatcalculates summary statistics for all columns. It recognizes the data type of the column and prints out descriptive information accordingly.csvstatmay be piped together withcsvcutto calculate descriptive statistics only for certain columns.The following command shows the summary statistics for the car, miles per gallon consumption and origin columns.
$ csvcut -c 1,2,9 -d ";" cars-tutorial.csv | csvstat | csvformat -D "."" 1. ""Car""" Type of data: Text Contains null values: False Unique values: 308 Longest value: 36 characters Most common values: Toyota Corolla (9x) Ford Pinto (6x) Ford Maverick (5x) AMC Matador (5x) Volkswagen Rabbit (5x) " 2. ""MPG""" Type of data: Number Contains null values: False Unique values: 130 Smallest value: 0 Largest value: 46.6 Sum: 9 358.8 Mean: 23.051 Median: 22.35 StDev: 8.402 Most common values: 13 (20x) 14 (19x) 18 (17x) 15 (16x) 26 (14x) " 3. ""Origin""" Type of data: Text Contains null values: False Unique values: 3 Longest value: 6 characters Most common values: US (254x) Japan (79x) Europe (73x) Row count: 406 -
csvsortsorts the rows for the column specified (either with a number or a name) after the argument-c. Reversed order can be set by using-r.Based on the previous example, the highest value in miles per gallon is 46.6. If you want to search for this very fuel efficient car, one way is to sort the data in a reversed order.
$ csvcut -c 1,2 -d ";" cars-tutorial.csv | csvsort -c 2 -r | head -5 | csvlook | csvformat -D "."The output shows the four most fuel efficient cars. Mazda GLC, the most fuel efficient one has indeed a 46.6 miles per gallon consumption.
| Car | MPG | | ---------------------------- | ---- | | Mazda GLC | 46.6 | | Honda Civic 1500 gl | 44.6 | | Volkswagen Rabbit C (Diesel) | 44.3 | | Volkswagen Pickup | 44.0 | -
csvgrepselects rows that match specific patterns, so in other words it can be used for filtering. The pattern may either be a string or an integer. The-cargument specifies the column in which the pattern is searched for (either the column number or name can be used), while -m defines the pattern.Following the previous examples, the car with the highest miles per gallon consumption (which is 46.6) is searched for.
$ csvgrep -c MPG -m 46.6 -d ";" cars-tutorial.csv | csvlook | csvformat -D "."The command yields the following output showing only cars with a 46.6 miles per gallon consumption. There is only one such car: Mazda GLC.
| Car | MPG | Cylinders | Displacement | Horsepower | Weight | Acceleration | Model | Origin | | --------- | ---- | --------- | ------------ | ---------- | ------ | ------------ | ----- | ------ | | Mazda GLC | 46.6 | 4 | 86 | 65 | 2 110 | 17.9 | 80 | Japan |It is also possible to filter and separate the file based on a string variable. In the following example three different csv files are created based on the origin variable. We know from the
csvstatcommand that there are three possible categories for origin: US, Japan and Europe.$ csvgrep -c Origin -m US -d ";" cars-tutorial.csv > cars-tutorial-us.csv $ csvgrep -c Origin -m Japan -d ";" cars-tutorial.csv > cars-tutorial-japan.csv $ csvgrep -c Origin -m Europe -d ";" cars-tutorial.csv > cars-tutorial-europe.csv -
csvstackappends datasets with identical column names. There might be cases where it makes sense to specify the-gargument which adds a column identifying the source csv. In the following example it is not needed.The three csv files created in the previous example can be stacked. Since there were three countries of origin, this command should have the same length as the original data.
$ csvstack cars-tutorial-us.csv cars-tutorial-europe.csv cars-tutorial-japan.csv $ csvstack cars-tutorial-us.csv cars-tutorial-europe.csv cars-tutorial-japan.csv | wc -l $ wc cars-tutorial.csv -lBoth files have 407 rows as expected (406 plus the header).
Useful resources for learning csvkit:
- The csvkit tutorial and documentation: https://csvkit.readthedocs.io/en/1.0.5/tutorial.html /
Key Points